Odstraňování problémů s HDD, SSD a HBA
Odstraňování problémů s HDD, SSD a HBA
Odstraňování problémů s HDD, SSD a HBA
Popis
Když na disku dochází k opravitelným chybám, varováním nebo úplnému selhání, služba Stargate označí disk jako offline. Pokud je disk detekován jako offline 3krát během hodiny, je automaticky odstraněn z clusteru a je vygenerováno upozornění ( KB-4158 nebo KB-6287 ).
Pokud se v Prism vygeneruje výstraha, je nutné vyměnit disk. Kroky pro odstraňování problémů není nutné provádět.
POZNÁMKA: Pokud v clusteru Nutanix na AWS narazíte na disk, který selhal, jakmile se potvrdí, že disk selhal, pokračujte k odsouzení příslušného uzlu. Odsouzení postiženého uzlu jej nahradí novou holou kovovou instancí stejného typu.
Řešení
Po výměně disku by měla být provedena kontrola stavu NCC, aby bylo zajištěno optimální stav clusteru.
Pokud však výstraha nebyla vygenerována nebo je nutná další analýza, lze k dalšímu odstraňování problémů použít níže uvedené kroky.
Než začnete s odstraňováním problémů, ověřte typ řadiče HBA.
Pozor:
Použití příkazu SAS3IRCU proti LSI 3408 nebo vyšším HBA může způsobit události NMI, které by mohly vést k nedostupnosti úložiště.
Před použitím následujících příkazů potvrďte ovladač HBA.
Chcete- li zjistit, jaký typ HBA se používá, vyhledejte název řadiče v /etc/nutanix/hardware_config.json v CVM.
- Příklad výstupu při použití SAS3008:
V tomto případě je správným příkazem příkaz SAS3IRCU .
Všimněte si řádku "led_address": "sas3ircu:0,1:0" :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Příklad výstupu při použití SAS3400/3800 (nebo novějšího):
V tomto případě by použití SAS3IRCU bylo nerozumné. Místo toho použijte příkaz storcli . Informace o StorCLI naleznete v KB-10951 .
Poznámka "led_address": řádek "storcli:0" .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Identifikujte problematické disky
- Zkontrolujte webovou konzolu Prism, zda neobsahuje vadný disk. V zobrazení Diagram můžete chybějící disk vidět červeně nebo šedě.
- Zkontrolujte webovou konzolu Prism pro upozornění na disky nebo použijte následující příkaz ke kontrole disků, které generují zprávy o selhání.
nutanix@cvm$ ncli alert ls - Zkontrolujte, zda v některých uzlech nechybí připojené disky. Tyto dva výstupy by se měly číselně shodovat.
- Zkontrolujte disky, které jsou připojeny k CVM (Controller VM).
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Zkontrolujte disky, které jsou fyzické v CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Zkontrolujte, zda je stav všech disků online a zda je označen jako Normální .
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Zkontrolujte disky, které jsou připojeny k CVM (Controller VM).
- Ověřte očekávaný počet disků v clusteru.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lVýstupem výše uvedeného příkazu by měl být součet výstupů kroků 1c.i a 1c.ii.
Existují případy, kdy může být číslo vyšší nebo nižší, než se očekávalo. Jde tedy o důležitou metriku, kterou lze porovnat s disky uvedenými v kroku 1b.
- Hledejte další nebo chybějící disky.
nutanix@cvm$ ncli disk ls - Zkontrolujte, zda jsou všechny disky označeny jako připojené rw (čtení-zápis) a nikoli ro (pouze pro čtení).
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Identifikujte problémy s uzly disků
- ID osiřelého disku
Toto je ID disku, které systémy již nepoužívají, ale nebylo správně odebráno. Příznaky zahrnují zobrazení zvláštního ID disku uvedeného ve výstupu ncli disk ls .
Postup opravy ID osiřelého disku:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueUjistěte se, že jste ověřili sériové číslo disku a že zařízení není v systému. Také se ujistěte, že se všechny disky naplňují pomocí lsscsi , mount , df -h a počítání disků pro celou populaci disku.
- Selhal disk a/nebo chybějící disk
Zkontrolujte, zda je disk viditelný pro řadič, protože je to zařízení, na jehož sběrnici je disk umístěn. Lze použít následující příkazy:
- lspci - zobrazí PCI zařízení, která vidí CVM.
- Zařízení NVME – Energeticky nezávislá paměťová karta: Intel Corporation PCIe Data Center SSD (rev 01).
- Řadič SAS3008 - Serial Attached SCSI řadič: LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) - LSI.
- Řadič SAS2308 (Dell) - Serial Attached SCSI řadič: LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (rev 05).
- MegaRaid LSI 3108 (Dell) - řadič sběrnice RAID: LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader] (rev 02).
- LSI SAS3108 (UCS) - Serial Attached SCSI řadič: LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (rev 02).
- lsiutil - zobrazuje perspektivu karet HBA (Host Bus Adapter) portů a zda jsou porty ve stavu UP. Pokud port není aktivní, zařízení buď neodpovědělo, nebo je port nebo připojení k zařízení špatné. Nejpravděpodobnějším problémem je zařízení (disk).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi – uvádí seznam zařízení sběrnice SCSI, která obsahují jakýkoli pevný disk nebo SSD (kromě NVME, které neprochází řadičem SATA).
- sas3ircu - hlásí pozici slotu a stav disku. Je to užitečné pro chybějící disky nebo ověření, že jsou disky ve správném slotu. (NEPOUŽÍVEJTE následující příkaz na hardwaru Lenovo HX, protože to může vést k zablokování a resetování HBA)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli – Hlásí chyby disku podobné lsiutil. Také hlásí polohu slotu a stav disku.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Zkontrolujte dmesg CVM pro zprávy LSI mpt3sas. Obvykle bychom měli vidět jednu položku pro každý fyzický slot. ( Níže uvedený příklad ukazuje, že adresa SAS "0x5000c5007286a3f5" je opakovaně kontrolována z důvodu špatného/selhání disku. Všimněte si, jak jsou jednou detekovány ostatní adresy a podezřelý je opakovaně dotazován. )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl - pokud Hades označí, že je disk kontrolován smartctl 3x za hodinu, automaticky selže.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- Odstraňování problémů s smartctl viz KB-8094 .
- Zkontrolujte offline disky pomocí NCC kontrola disk_online_check .
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Další řešení problémů s offline disky viz KB 1536 .
- Potvrďte, zda jsou disky vidět z nástroje LSI Config Utility. To může být užitečné pro vyloučení potenciálních problémů s konfigurací driver nebo CVM/Hypervisoru, které by vám mohly bránit v detekci určitých jednotek. LSI Config Utility vám poskytuje rozhraní přímo k firmwaru HBA, aniž byste se spoléhali na softwarový operační systém. Lze jej použít k mnoha stejným věcem, které můžete dělat s "lsiutil": (a) Kontrola, zda je disk detekován v konkrétním slotu, (b) Kontrola rychlosti připojení disku, (c) Aktivace LED majáku na konkrétním disku. Na platformách G6 a G7 je LSI Config Menu ve výchozím nastavení zakázáno, takže před použitím jej musíte povolit v BIOS . Na platformách G8 musíte připojené jednotky zobrazit přímo prostřednictvím nabídky BIOS .
- G8: Zobrazte připojené jednotky přímo prostřednictvím BIOS
- Vstupte do nabídky BIOS stisknutím klávesy DEL na úvodní obrazovce "Nutanix", zatímco se uzel spouští.
- Přejděte na kartu " Upřesnit " a vyberte " Konfigurace SCC-B8SB80-B1 (PCISlot=0x8) ". Tak se nazývá volba nabídky na 3060-G8. U jiných modelů se může jmenovat trochu jinak.
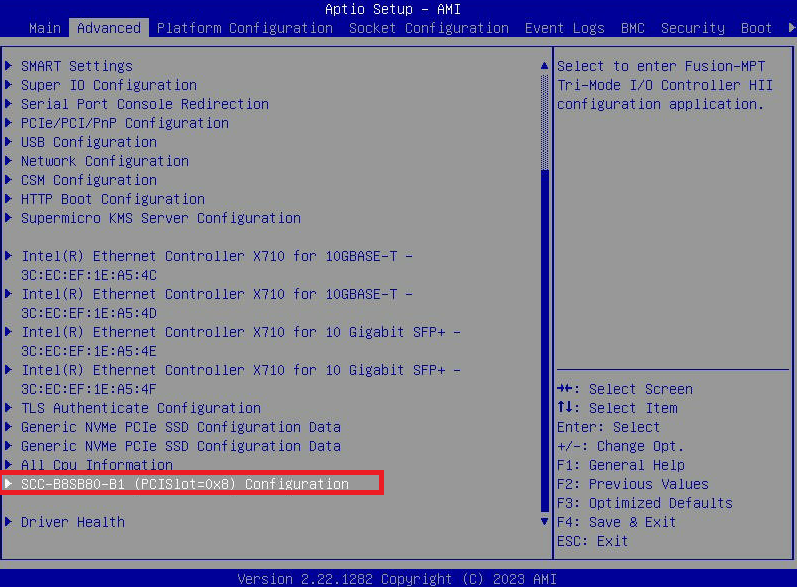
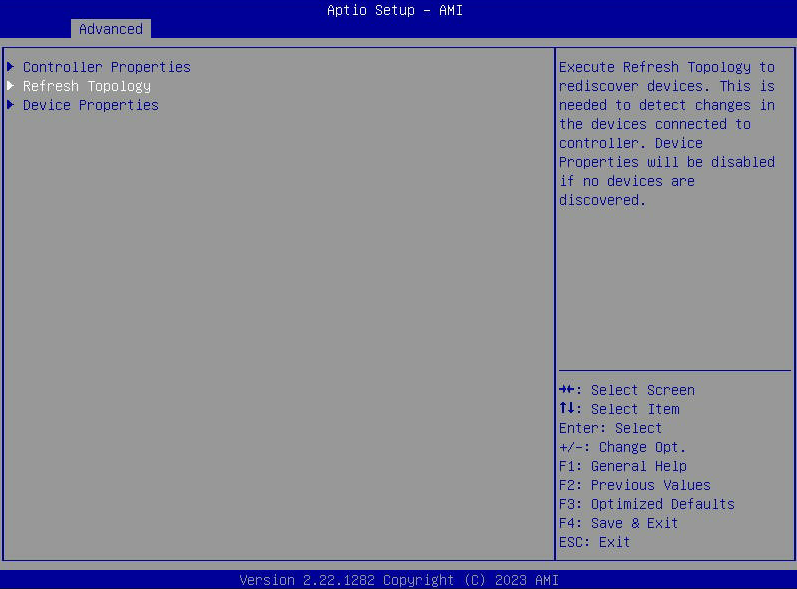
- G8: Zobrazte připojené jednotky přímo prostřednictvím BIOS
- lspci - zobrazí PCI zařízení, která vidí CVM.
- ID osiřelého disku
- Pokud je možnost „Vlastnosti zařízení“ zašedlá, vyberte „Obnovit topologii“.
- Chcete-li zobrazit seznam disků SATA viditelných hostiteli, vyberte „Vlastnosti disku“.
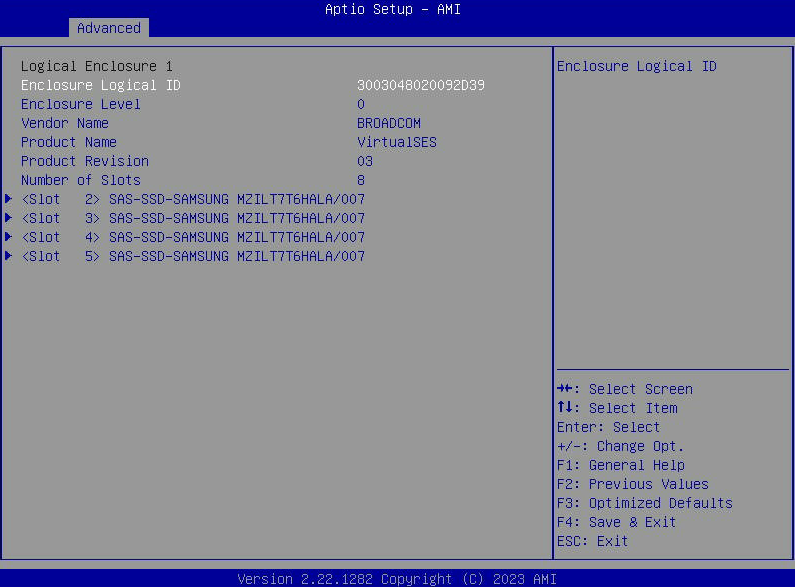
- G6 & G7: Jak povolit a získat přístup k LSI HBA OPROM
- Vstupte do nabídky BIOS stisknutím klávesy DEL na úvodní obrazovce "Nutanix", zatímco se uzel spouští.
- Přejděte na kartu "Upřesnit" a najděte "LSI HBA OPROM". Nastavte toto na "Povoleno". Poté stiskněte "F4" pro "Uložit a ukončit" nabídku BIOS . To způsobí restart uzlu.
- Poznámka: Jakmile získáte potřebné informace, vraťte se zpět do BIOS a ZAKÁZEJTE OPROM. Můžete také stisknout F3 pro načtení optimalizovaných výchozích hodnot, čímž se BIOS vrátí do původního továrního nastavení, kde je OPROM deaktivována.
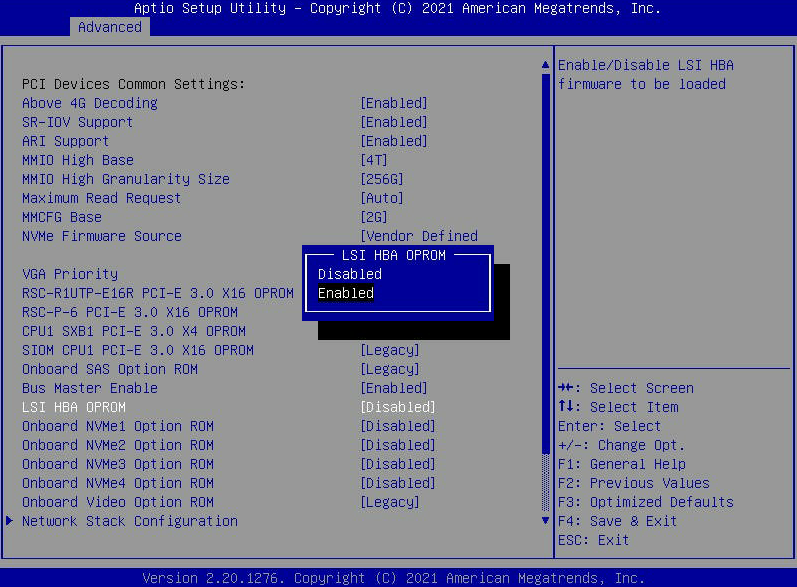
- Při příštím spuštění vyhledejte obrazovku s názvem „Avago Technologies MPT SAS3 BIOS “ a stiskněte CRTL+C pro vstup do „SAS Configuration Utility“.
- V nástroji Config Utility vyberte kartu HBA, která vás zajímá. Modely s více uzly (2U4N, 2U2N) budou mít maximálně jednu kartu HBA, zatímco platformy s jedním uzlem (2U1N) mohou mít až tři. V systémech s více HBA bude každý HBA obsluhovat jinou podmnožinu jednotek na každém uzlu.
- Na další obrazovce vyberte "SAS Topology" a poté "Direct Attach Devices" pro zobrazení informací o jednotkách spojených s daným HBA.
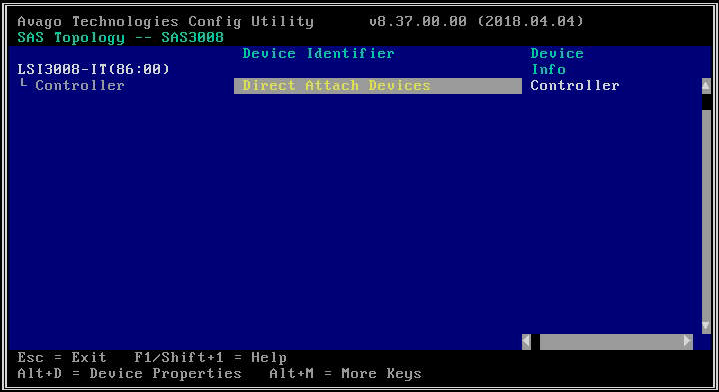
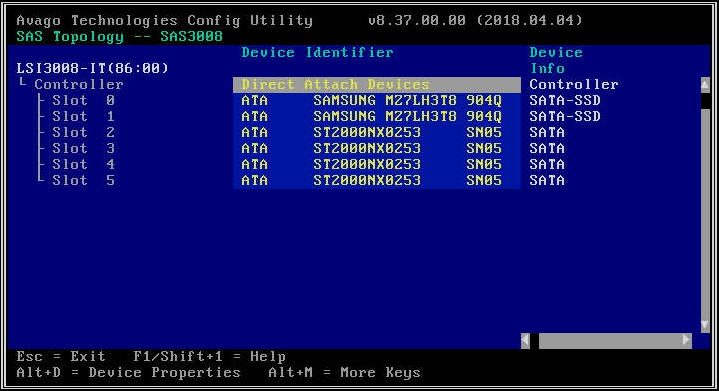
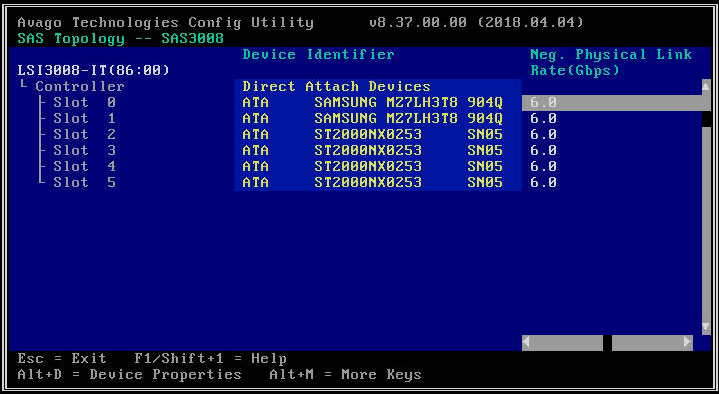
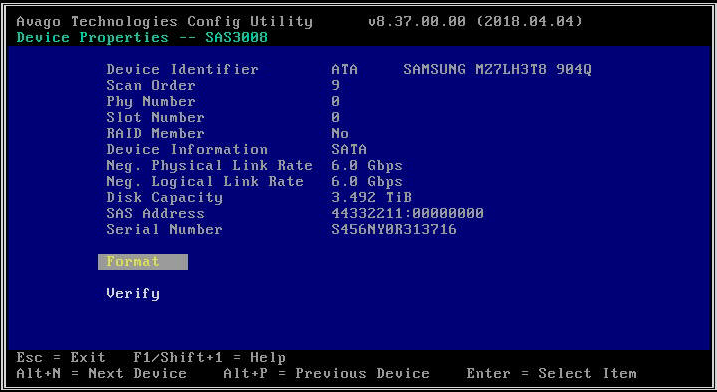
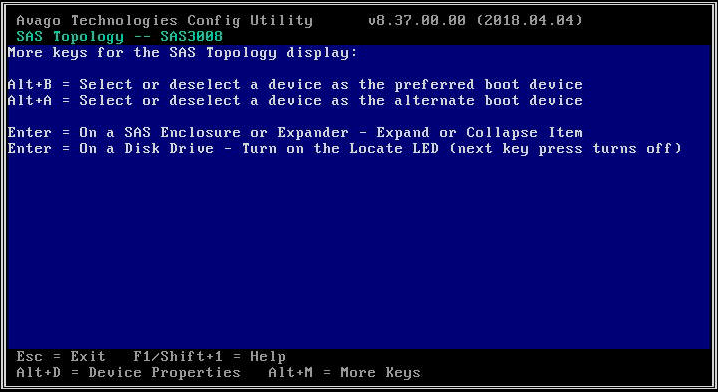
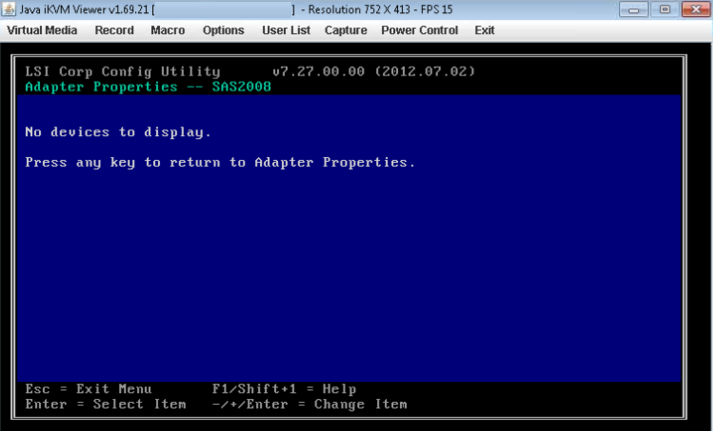
- Pokud vybraný adaptér HBA nedetekuje vůbec žádné jednotky, ohlásí „Žádná zařízení k zobrazení“.
- Může nastat případ, kdy je disk v lsiutil DOWN, obvykle po výměně nebo upgradu disků. Když jsou provedeny všechny výše uvedené kontroly a disk stále není viditelný, porovnejte starý a nový disk „kaddy nebo zásobník disku“. Ujistěte se, že typ je stejný. Mohou nastat případy, kdy je odeslán nesprávný typ disku, který není správně usazen v diskové šachtě, a proto jej řadič nezjistí.

- Identifikujte typ uzlu nebo problematický uzel.
Spusťte ncli host ls a najděte odpovídající ID uzlu. Specifické umístění slotu uzlu, sériové číslo uzlu a typ uzlu jsou důležité informace, které je třeba zdokumentovat v případě opakujících se problémů. Pomáhá také sledovat problémy v terénu s HBA, umístěními uzlů a typy uzlů. - Identifikujte výskyt poruchy.
- Zkontrolujte protokol hvězdné brány. Protokol stargate.INFO za odpovídající období ukazuje, zda Stargate zaznamenala problém s diskem a odeslala jej do Správce disků (Hades) ke kontrole nebo zda měla jiné chyby při přístupu k disku. Použijte ID a sériové číslo disku k vyhledání v protokolu hvězdné brány na odpovídajícím uzlu, ve kterém se disk nachází.
- Protokol Hades obsahuje informace o discích, které vidí, a stavu disků. Také zkontroluje, který disk je metadata nebo disk Curator, a vybere jeden, pokud již v systému neexistoval nebo byl ze systému odstraněn/zmizel. Zkontrolujte protokol Hades.
- Zkontrolujte df -h v / home/nutanix/data/logs/sysstats/df.INFO, abyste viděli, kdy byl disk naposledy připojen.
- Podívejte se na /home/nutanix/data/logs/sysstats/iostat.INFO , abyste viděli, kdy bylo zařízení naposledy viděno.
- Zkontrolujte /home/log/messages, zda na zařízení nejsou chyby, konkrétně použijte název zařízení, například sda nebo sdc.
- Zkontrolujte dmesg , zda neobsahuje chyby na ovladači nebo zařízení. Spustit dmesg | méně pro aktuální zprávy v kruhu, nebo se podívejte na protokolovaný výstup dmesg v /var/log .
- Identifikujte příčinu selhání disku.
- Zkontrolujte, kdy bylo naposledy spuštěno CVM, pokud nebyla k dispozici data o posledním využití disku. Znovu se podívejte na hvězdnou bránu a protokoly Hádes.
- Zkontrolujte protokol hvězdné brány kolem doby selhání disku. Hvězdná brána pošle Hádovi disk, aby zkontroloval, zda v daném čase neodpovídá, a proti tomuto disku vyprší časový limit. Různé chyby a verze jej představují odlišně, takže vždy hledejte podle ID disku a sériového čísla disku.
- Zkontrolujte počet selhání disku.
Pokud by disk v tomto slotu selhal více než jednou a disk byl vyměněn, znamenalo by to potenciální problém v šasi. - Zkontrolujte, zda lsiutil zobrazuje chyby.
Pokud lsiutil zobrazuje chyby rovnoměrně na více slotech, může to znamenat špatný řadič. - Zkontrolujte známé problémy s FW disku pro chyby disku.
- Pokud se jedná o G8, verze MCU je 1.1A nebo vyšší a že byly upgradovány také základní desky:
Podívejte se na tento dokument: NX-G8: Nutanix Backplane CPLD, Základní deska CPLD a příručka pro upgrade firmwaru Multinode EC . - Pokud se jedná o G8, zkontrolujte, zda je FW řadiče LSI 25.00.00 nebo vyšší:
Existují opravy související se stabilitou SSD při použití trimu, které opravují instanci, která způsobuje chyby PHY na jednotkách a nestabilitu. Z hlediska řešení problémů je také důležité být na FW 25.00.00 nebo vyšší.
Poznámka: ID události: 191 , G-Sense_Error_Rate ve výstupu " smartctl " pro pevné disky Seagate lze bezpečně ignorovat, pokud nedojde ke snížení výkonu. Hodnota G-Sense_Error_Rate pouze indikuje, že se HDD přizpůsobuje detekci otřesů nebo vibrací. Seagate doporučuje těmto hodnotám nedůvěřovat, protože tento čítač dynamicky mění práh během běhu.
Související články
- Původní článek na portálu Nutanix: Nutanix KB Článek: 1113
- Vstupní stránka Nutanix
