Dépannage des disques durs, SSD et HBA
Dépannage des disques durs, SSD et HBA
Dépannage des disques durs, SSD et HBA
Description
Lorsqu'un disque rencontre des erreurs récupérables, des avertissements ou une panne complète, le service Stargate marque le disque comme hors ligne. Si le disque est détecté comme étant hors ligne 3 fois au cours de l'heure, il est automatiquement supprimé du cluster et une alerte est générée ( KB-4158 ou KB-6287 ).
Si une alerte est générée dans Prism, le disque doit être remplacé. Il n'est pas nécessaire d'effectuer des étapes de dépannage.
REMARQUE : Si un disque défaillant est rencontré dans un cluster Nutanix sur AWS, une fois que la défaillance du disque est confirmée, procédez à la condamnation du nœud concerné. Condamner le nœud concerné le remplacera par une nouvelle instance nue du même type.
Solution
Une fois le disque remplacé, une vérification de l'état NCC doit être effectuée pour garantir une santé optimale du cluster.
Toutefois, si aucune alerte n'a été générée en premier lieu ou si une analyse plus approfondie est requise, les étapes ci-dessous peuvent être utilisées pour un dépannage plus approfondi.
Avant de commencer le dépannage, vérifiez le type de contrôleur HBA.
Prudence:
L'utilisation de la commande SAS3IRCU sur un HBA LSI 3408 ou supérieur peut provoquer des événements NMI pouvant entraîner une indisponibilité du stockage.
Confirmez le contrôleur HBA avant d'utiliser les commandes suivantes.
Pour déterminer quel type de HBA est utilisé, recherchez le nom du contrôleur situé dans /etc/nutanix/hardware_config.json sur le CVM .
- Exemple de sortie lorsque SAS3008 est utilisé :
Dans ce cas, la commande SAS3IRCU est la bonne commande à utiliser.
Notez la ligne "led_address": "sas3ircu:0,1:0" :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Exemple de résultat lorsque SAS3400/3800 (ou plus récent) est utilisé :
Dans ce cas, utiliser SAS3IRCU serait déconseillé. Utilisez plutôt la commande storcli . Pour plus d’informations sur StorCLI, reportez-vous à KB-10951 .
Notez la ligne "led_address": "storcli:0" .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Identifiez les disques problématiques
- Vérifiez la console Web Prism pour le disque défaillant. Dans la vue Diagramme, vous pouvez voir du rouge ou du gris pour le disque manquant.
- Vérifiez la console Web Prism pour les alertes de disque ou utilisez la commande suivante pour rechercher les disques qui génèrent les messages d'échec.
nutanix@cvm$ ncli alert ls - Vérifiez s'il manque des disques montés à des nœuds. Les deux sorties doivent correspondre numériquement.
- Vérifiez les disques montés sur le CVM (Controller VM).
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Vérifiez les disques physiques dans le CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Vérifiez si l'état des disques est entièrement en ligne et indiqué comme Normal .
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Vérifiez les disques montés sur le CVM (Controller VM).
- Validez le nombre attendu de disques dans le cluster.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lLe résultat de la commande ci-dessus doit être la somme des résultats des étapes 1c.i et 1c.ii.
Il existe des cas où le nombre peut être supérieur ou inférieur à celui prévu. Il s’agit donc d’une mesure importante qui peut être comparée aux disques répertoriés à l’étape 1b.
- Recherchez les disques supplémentaires ou manquants.
nutanix@cvm$ ncli disk ls - Vérifiez que tous les disques sont indiqués comme montés rw (lecture-écriture) et non ro (lecture seule).
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Identifier les problèmes avec les nœuds de disques
- ID de disque orphelin
Il s'agit d'un ID de disque que les systèmes n'utilisent plus mais qui n'a pas été correctement supprimé. Les symptômes incluent la visualisation d'un ID de disque supplémentaire répertorié dans la sortie de ncli disk ls .
Pour corriger l'ID du disque orphelin :
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueAssurez-vous de valider le numéro de série du disque et que le périphérique n'est pas dans le système. Assurez-vous également que tous les disques sont remplis à l'aide de lsscsi , mount , df -h et que vous comptez les disques pour l'ensemble du disque.
- Disque défaillant et/ou disque manquant
Vérifiez si le disque est visible par le contrôleur car il s'agit du périphérique sur le bus sur lequel réside le disque. Les commandes suivantes peuvent être utilisées :
- lspci - affiche les périphériques PCI vus par le CVM.
- Périphérique NVME - Contrôleur de mémoire non volatile : SSD Intel Corporation PCIe Data Center (rév 01).
- Contrôleur SAS3008 - Contrôleur SCSI connecté en série : LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rév 02) - LSI.
- Contrôleur SAS2308 (Dell) - Contrôleur SCSI connecté en série : LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (rév 05).
- MegaRaid LSI 3108 (Dell) - Contrôleur de bus RAID : LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader] (rév 02).
- LSI SAS3108 (UCS) - Contrôleur SCSI connecté en série : LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (rév 02).
- lsiutil - affiche la perspective des cartes HBA (Host Bus Adapter) des ports et si les ports sont dans un état UP. Si un port n'est pas actif, soit le périphérique n'a pas répondu, soit le port ou la connexion au périphérique est mauvais. Le problème le plus probable est le périphérique (disque).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi - répertorie les périphériques de bus SCSI qui incluent n'importe quel disque dur ou SSD (à l'exception de NVME, qui ne passe pas par le contrôleur SATA).
- sas3ircu - rapporte la position de l'emplacement et l'état du disque. Ceci est utile en cas de disques manquants ou pour vérifier que les disques sont dans le bon emplacement. (N'exécutez PAS la commande suivante sur le matériel Lenovo HX car cela pourrait entraîner des blocages et des réinitialisations du HBA)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli - Signale les erreurs de lecteur similaires à lsiutil. Rapporte également la position de l'emplacement et l'état du disque.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Vérifiez le dmesg du CVM pour les messages LSI mpt3sas. Nous devrions généralement voir une entrée pour chaque emplacement physique. ( L'exemple ci-dessous montre que l'adresse SAS "0x5000c5007286a3f5" est vérifiée à plusieurs reprises en raison d'un disque défectueux/en panne. Notez comment les autres adresses sont détectées une fois et le suspect est interrogé à plusieurs reprises. )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl - si Hadès indique qu'un disque est vérifié par smartctl 3 fois en une heure, il échoue automatiquement.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- Voir KB-8094 pour le dépannage avec smartctl .
- Recherchez les disques hors ligne à l'aide de NCC check disk_online_check .
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Consultez la base de connaissances 1536 pour plus de dépannage sur les disques hors ligne.
- Confirmez si les disques sont visibles à partir de l'utilitaire de configuration LSI. Cela peut être utile pour exclure les problèmes potentiels driver ou de configuration CVM/hyperviseur qui pourraient vous empêcher de détecter certains lecteurs. L'utilitaire de configuration LSI vous offre une interface directement avec le micrologiciel HBA sans recourir à un système d'exploitation logiciel. Il peut être utilisé pour faire plusieurs des mêmes choses que vous pouvez faire avec "lsiutil": (a) Vérifier si un disque est détecté dans un emplacement particulier, (b) Vérifier la vitesse d'une liaison de disque, (c) Activer une balise LED sur un lecteur particulier. Sur les plateformes G6 et G7, le menu de configuration LSI est désactivé par défaut, vous devez donc l'activer dans le BIOS avant de pouvoir l'utiliser. Sur les plates-formes G8, vous devez afficher les disques connectés directement via le menu BIOS .
- G8 : affichez les disques connectés directement via le BIOS
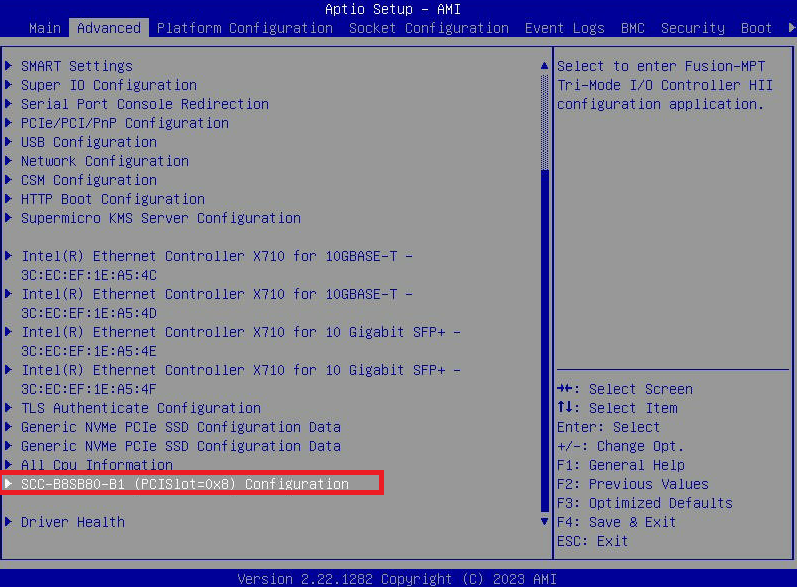
- Entrez dans le menu BIOS en appuyant sur la touche DEL sur l'écran de démarrage "Nutanix" pendant le démarrage du nœud.
- Allez dans l'onglet « Avancé » et sélectionnez « Configuration SCC-B8SB80-B1 (PCISlot=0x8) ». C'est ainsi que s'appelle l'option de menu sur le 3060-G8. Il peut être nommé légèrement différemment sur d'autres modèles.
- G8 : affichez les disques connectés directement via le BIOS
- lspci - affiche les périphériques PCI vus par le CVM.
- ID de disque orphelin
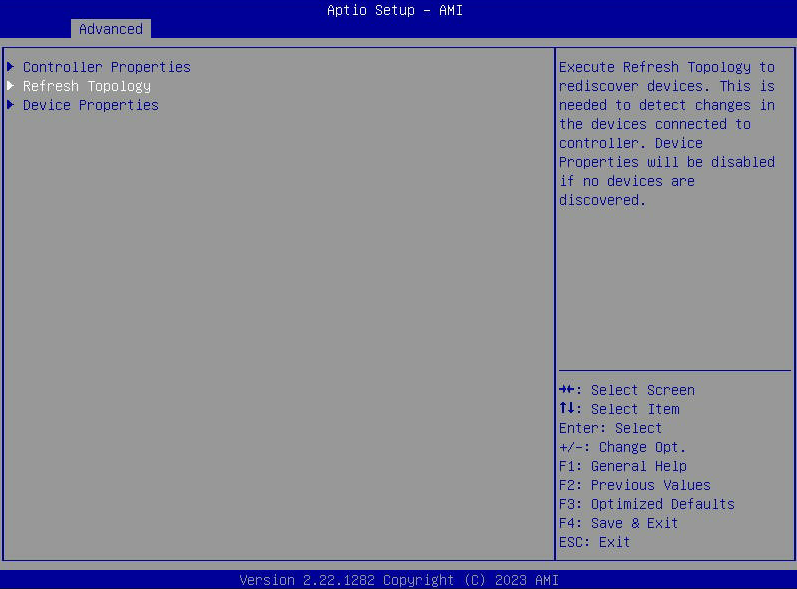
- Si l'option « Propriétés du périphérique » est grisée, sélectionnez « Actualiser la topologie ».
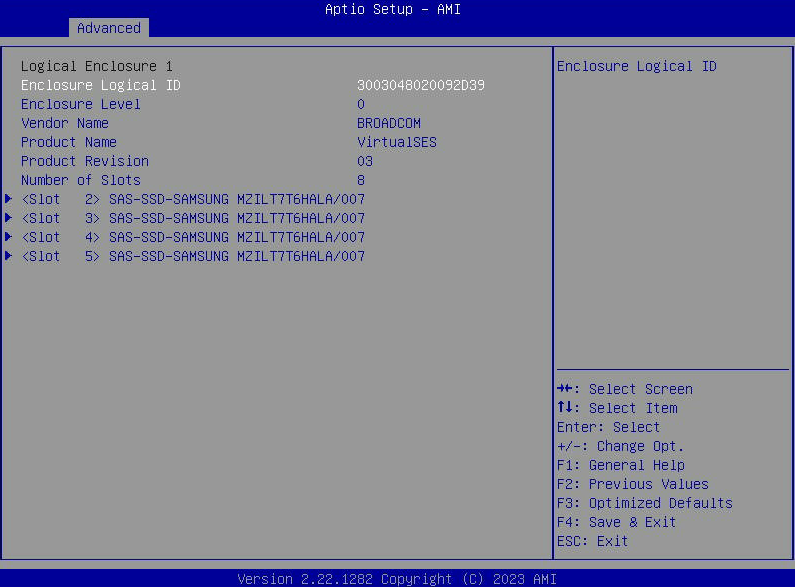
- Sélectionnez "Propriétés du lecteur" pour voir une liste des disques SATA visibles par l'hôte.
- G6 et G7 : Comment activer et accéder à LSI HBA OPROM
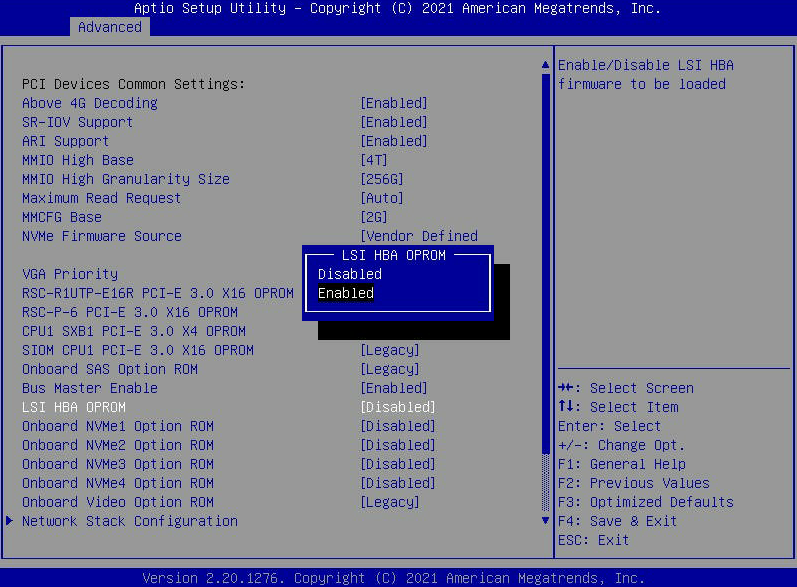
- Entrez dans le menu BIOS en appuyant sur la touche DEL sur l'écran de démarrage "Nutanix" pendant le démarrage du nœud.
- Allez dans l'onglet "Avancé" et recherchez "LSI HBA OPROM". Réglez-le sur "Activé". Appuyez ensuite sur « F4 » pour « Enregistrer et quitter » le menu BIOS . Cela entraînera le redémarrage du nœud.
- Remarque : Après avoir obtenu les informations dont vous avez besoin, assurez-vous de revenir dans le BIOS et de DÉSACTIVER l'OPROM. Vous pouvez également appuyer sur F3 pour charger les paramètres par défaut optimisés, ce qui ramènera le BIOS à ses paramètres d'usine d'origine où l'OPROM est désactivée.
- Au prochain démarrage, recherchez l'écran intitulé « Avago Technologies MPT SAS3 BIOS » et appuyez sur CRTL+C pour accéder à « Utilitaire de configuration SAS ».
- Une fois dans l'utilitaire de configuration, sélectionnez la carte HBA qui vous intéresse. Les modèles multi-nœuds (2U4N, 2U2N) n'auront qu'un maximum d'une carte HBA, tandis que les plates-formes à nœud unique (2U1N) peuvent en avoir jusqu'à trois. Dans les systèmes multi-HBA, chaque HBA servira un sous-ensemble différent de disques sur chaque nœud.
- Sur l'écran suivant, sélectionnez « Topologie SAS », puis « Périphériques à connexion directe » pour afficher des informations sur les lecteurs associés à ce HBA.
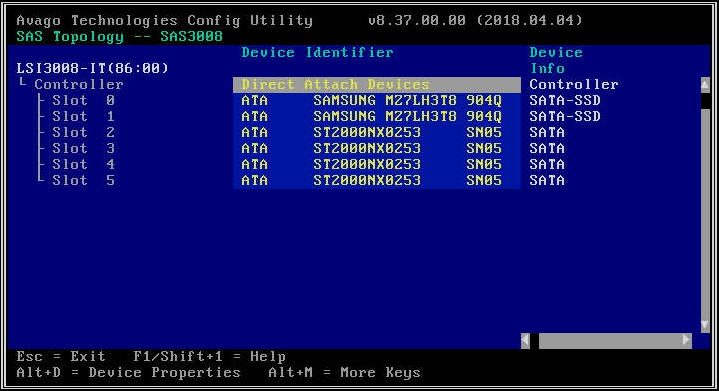
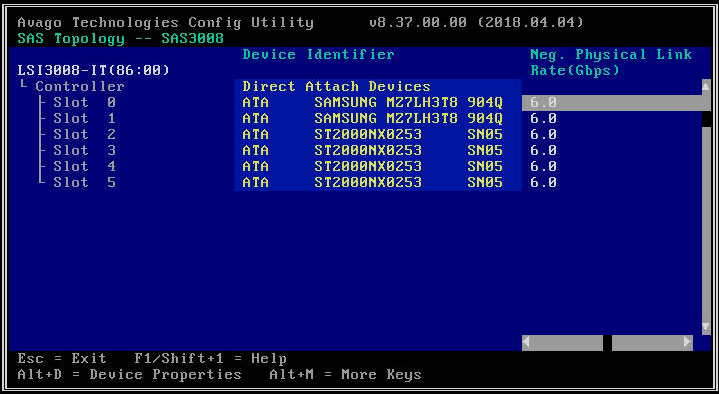
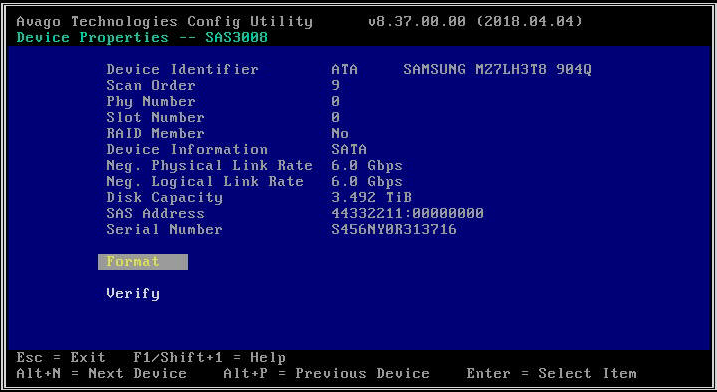
- Si le HBA que vous avez sélectionné ne détecte aucun lecteur, il affichera « Aucun périphérique à afficher ».
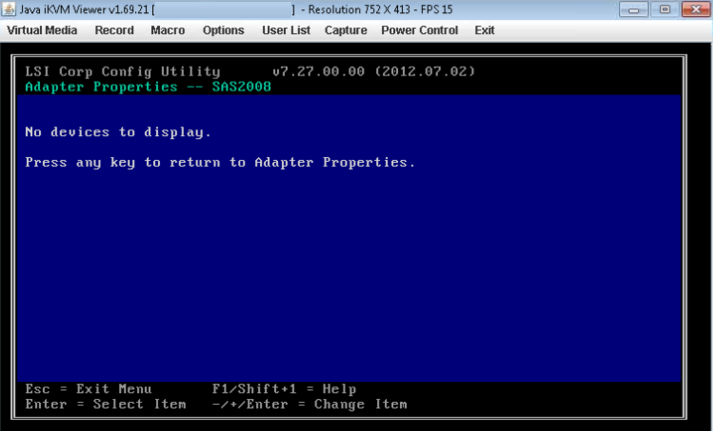
- Il peut arriver que le disque soit DOWN dans lsiutil , généralement après un remplacement ou une mise à niveau des disques. Lorsque toutes les vérifications ci-dessus sont effectuées et que le disque n'est toujours pas visible, comparez l'ancien et le nouveau disque "caddy ou plateau de disque". Assurez-vous que le type est le même. Il peut y avoir des cas où un type de disque incorrect est distribué et il ne s'insère pas correctement dans la baie de disque et n'est donc pas détecté par le contrôleur.

- Identifiez le type de nœud ou le nœud problématique.
Exécutez ncli host ls et recherchez l'ID de nœud correspondant. L'emplacement spécifique de l'emplacement du nœud, le numéro de série du nœud et le type de nœud sont des informations importantes à documenter en cas de problèmes récurrents. Cela permet également de suivre les problèmes sur le terrain avec les HBA, les emplacements et les types de nœuds. - Identifiez l’occurrence de l’échec.
- Vérifiez le journal Stargate. Le journal stargate.INFO pour la période correspondante indique si Stargate a détecté un problème avec un disque et l'a envoyé au gestionnaire de disque (Hades) pour être vérifié ou si d'autres erreurs ont eu lieu lors de l'accès au disque. Utilisez le numéro d'identification du disque et le numéro de série à rechercher dans le journal Stargate sur le nœud correspondant dans lequel se trouve le disque.
- Le journal Hades contient des informations sur les disques qu'il voit et sur l'état des disques. Il vérifie également quel disque est un disque de métadonnées ou un disque de conservateur et en sélectionne un s'il n'en existait pas déjà un dans le système ou s'il a été supprimé/disparu du système. Vérifiez le journal Hadès.
- Vérifiez df -h dans /home/nutanix/data/logs/sysstats/df.INFO pour voir quand le disque a été vu pour la dernière fois comme monté.
- Vérifiez /home/nutanix/data/logs/sysstats/iostat.INFO pour voir quand l'appareil a été vu pour la dernière fois.
- Recherchez dans /home/log/messages les erreurs sur le périphérique, en particulier en utilisant le nom du périphérique, par exemple sda ou sdc.
- Vérifiez dmesg pour les erreurs sur le contrôleur ou le périphérique. Exécutez dmesg | less pour les messages actuels dans l'anneau, ou regardez la sortie dmesg enregistrée dans /var/log .
- Identifiez la cause de la panne de disque.
- Vérifiez quand le CVM a été démarré pour la dernière fois si les dernières données d'utilisation du disque n'étaient pas disponibles. Encore une fois, faites référence aux journaux Stargate et Hadès.
- Vérifiez le journal Stargate au moment de la panne de disque. Stargate envoie un disque à Hadès pour vérifier s'il ne répond pas dans un délai donné et expire le délai d'exécution des opérations sur ce disque. Différentes erreurs et versions le représentent différemment, alors recherchez toujours par ID de disque et numéro de série du disque.
- Vérifiez le nombre de pannes de disque.
Si un lecteur tombait en panne plus d'une fois dans cet emplacement et que le disque était remplacé, cela indiquerait un problème potentiel de châssis à ce stade. - Vérifiez si lsiutil affiche des erreurs.
Si lsiutil affiche des erreurs uniformément sur plusieurs emplacements, cela peut indiquer un contrôleur défectueux. - Recherchez les problèmes connus avec le micrologiciel du lecteur pour les erreurs de disque.
- S'il s'agit d'un G8, que la version du MCU est 1.1A ou supérieure et que les fonds de panier ont également été mis à niveau :
Référencez ce document : NX-G8 : Guide de mise à niveau manuelle du micrologiciel Nutanix Backplane CPLD, de la carte mère CPLD et du micrologiciel Multinode EC . - S'il s'agit d'un G8, vérifiez que le micrologiciel du contrôleur LSI est 25.00.00 ou supérieur :
Il existe des correctifs liés à la stabilité du SSD lorsque Trim est utilisé, qui corrigent une instance provoquant l'apparition d'erreurs PHY sur les disques et l'instabilité. Il est également important, du point de vue du dépannage, d'être sur FW 25.00.00 ou supérieur.
Remarque : ID d'événement : 191 , G-Sense_Error_Rate dans la sortie " smartctl " pour les disques durs Seagate peut être ignoré en toute sécurité, sauf en cas de dégradation des performances. La valeur G-Sense_Error_Rate indique uniquement que le disque dur s'adapte à la détection de chocs ou de vibrations. Seagate recommande de ne pas faire confiance à ces valeurs car ce compteur modifie dynamiquement le seuil pendant l'exécution.
Articles connexes
- Article original dans le portail Nutanix : Article de la base de connaissances Nutanix : 1113
- Page de destination de Nutanix
