Solução de problemas de HDD, SSD e HBA
Solução de problemas de HDD, SSD e HBA
Solução de problemas de HDD, SSD e HBA
Descrição
Quando uma unidade apresenta erros recuperáveis, avisos ou uma falha completa, o serviço Stargate marca o disco como offline. Se for detectado que o disco está off-line 3 vezes em uma hora, ele será removido do cluster automaticamente e um alerta será gerado ( KB-4158 ou KB-6287 ).
Se um alerta for gerado no Prism, o disco deverá ser substituído. As etapas de solução de problemas não precisam ser executadas.
NOTA: Se um disco com falha for encontrado em um cluster Nutanix na AWS, assim que for confirmado que o disco falhou, prossiga para condenar o respectivo nó. Condenar o nó afetado irá substituí-lo por uma nova instância bare metal do mesmo tipo.
Solução
Depois que o disco for substituído, uma verificação de integridade do NCC deverá ser realizada para garantir a integridade ideal do cluster.
No entanto, se um alerta não foi gerado em primeiro lugar ou se for necessária uma análise mais aprofundada, as etapas abaixo poderão ser usadas para solucionar problemas adicionais.
Antes de começar a solucionar problemas, verifique o tipo de controlador HBA.
Cuidado:
Usar o comando SAS3IRCU em um HBA LSI 3408 ou superior pode causar eventos NMI que podem levar à indisponibilidade de armazenamento.
Confirme o controlador HBA antes de usar os comandos a seguir.
Para determinar que tipo de HBA é usado, procure o nome do controlador localizado em /etc/nutanix/hardware_config.json na CVM .
- Exemplo de saída quando SAS3008 é usado:
Neste caso, o comando SAS3IRCU é o comando correto a ser utilizado.
Observe a linha "led_address": "sas3ircu:0,1:0" :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Exemplo de saída quando SAS3400/3800 (ou mais recente) é usado:
Neste caso, usar SAS3IRCU seria desaconselhável. Use o comando storcli . Para informações sobre o StorCLI consulte KB-10951 .
Observe a linha "led_address": "storcli:0" .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Identifique os discos problemáticos
- Verifique o console da Web do Prism para encontrar o disco com falha. Na visualização Diagrama, você pode ver vermelho ou cinza para o disco ausente.
- Verifique se há alertas de disco no console da Web do Prism ou use o comando a seguir para verificar os discos que geram as mensagens de falha.
nutanix@cvm$ ncli alert ls - Verifique se algum nó está faltando discos montados. As duas saídas devem corresponder numericamente.
- Verifique os discos que estão montados na CVM (VM Controladora).
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Verifique os discos físicos na CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Verifique se o status dos discos está todo Online e indicado como Normal .
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Verifique os discos que estão montados na CVM (VM Controladora).
- Valide o número esperado de discos no cluster.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lA saída do comando acima deve ser a soma das saídas das etapas 1c.i e 1c.ii.
Há casos em que o número pode ser maior ou menor do que o esperado. Portanto, é uma métrica importante que pode ser comparada aos discos listados na etapa 1b.
- Procure discos extras ou ausentes.
nutanix@cvm$ ncli disk ls - Verifique se todos os discos estão indicados como montados rw (leitura-gravação) e não ro (somente leitura).
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Identifique os problemas com os nós dos discos
- ID do disco órfão
Este é um ID de disco que os sistemas não usam mais, mas que não foi removido corretamente. Os sintomas incluem ver um ID de disco extra listado na saída de ncli disk ls .
Para corrigir o ID do disco órfão:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueCertifique-se de validar o número de série do disco e de que o dispositivo não esteja no sistema. Além disso, certifique-se de que todos os discos estejam sendo preenchidos usando lsscsi , mount , df -h e contando os discos para o preenchimento completo do disco.
- Disco com falha e/ou disco ausente
Verifique se o disco está visível para o controlador, pois é o dispositivo em cujo barramento o disco reside. Os seguintes comandos podem ser usados:
- lspci – exibe os dispositivos PCI vistos pela CVM.
- Dispositivo NVME - Controlador de memória não volátil: Intel Corporation PCIe Data Center SSD (rev 01).
- Controlador SAS3008 - Controlador SCSI conectado em série: LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) - LSI.
- Controlador SAS2308 (Dell) - Controlador SCSI conectado em série: LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (rev 05).
- MegaRaid LSI 3108 (Dell) - Controlador de barramento RAID: LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader] (rev 02).
- LSI SAS3108 (UCS) - Controlador SCSI conectado em série: LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (rev 02).
- lsiutil - exibe a perspectiva das placas HBA (Host Bus Adapter) das portas e se as portas estão no estado UP. Se uma porta não estiver ativa, o dispositivo não respondeu ou a porta ou a conexão com o dispositivo está ruim. O problema mais provável é o dispositivo (disco).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi - lista os dispositivos de barramento SCSI vistos que incluem qualquer HDD ou SSD (exceto NVME, que não passa pelo controlador SATA).
- sas3ircu - relata a posição do slot e o estado do disco. É útil para discos ausentes ou para verificar se os discos estão no slot correto. (NÃO execute o seguinte comando no hardware Lenovo HX, pois isso pode levar a travamentos e reinicializações do HBA)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli - Relata erros de unidade semelhantes ao lsiutil. Também informa a posição do slot e o estado do disco.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Verifique o dmesg da CVM para mensagens LSI mpt3sas. Normalmente deveríamos ver uma entrada para cada slot físico. ( O exemplo abaixo mostra que o endereço SAS "0x5000c5007286a3f5" é verificado repetidamente devido a um disco defeituoso/com falha. Observe como os outros endereços são detectados uma vez e o suspeito está sendo pesquisado repetidamente. )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl - se Hades indicar que um disco é verificado pelo smartctl 3 vezes em uma hora, ele falhará automaticamente.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- Consulte KB-8094 para solução de problemas com smartctl .
- Verifique se há discos offline usando NCC check disk_online_check .
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Consulte KB 1536 para obter mais soluções de problemas de discos offline.
- Confirme se os discos são vistos no LSI Config Utility. Isso pode ser útil para descartar possíveis problemas de configuração de driver ou CVM/hipervisor que podem impedir a detecção de determinadas unidades. O LSI Config Utility oferece uma interface diretamente para o firmware do HBA sem depender de um sistema operacional de software. Ele pode ser usado para fazer muitas das mesmas coisas que você pode fazer com "lsiutil": (a) Verificar se um disco é detectado em um slot específico, (b) Verificar a velocidade do link do disco, (c) Ativar um farol LED em uma unidade específica. Nas plataformas G6 e G7, o menu de configuração LSI está desabilitado por padrão, então você deve habilitá-lo no BIOS antes de poder usá-lo. Nas plataformas G8 você deve visualizar as unidades conectadas diretamente através do menu BIOS .
- G8: Visualize unidades conectadas diretamente através do BIOS
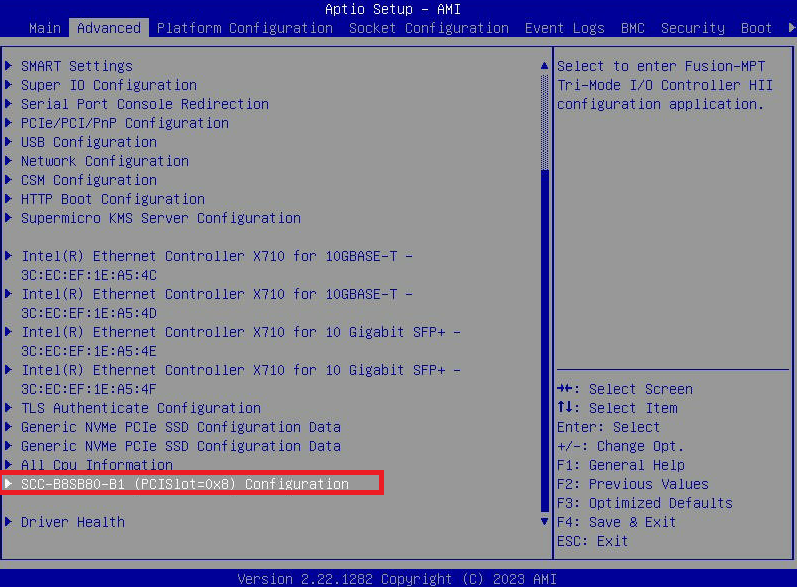
- Entre no menu BIOS pressionando a tecla DEL na tela inicial “Nutanix” enquanto o nó está inicializando.
- Vá para a guia " Avançado " e selecione " Configuração SCC-B8SB80-B1 (PCISlot=0x8) ". É assim que a opção de menu é chamada no 3060-G8. Pode ter um nome ligeiramente diferente em outros modelos.
- G8: Visualize unidades conectadas diretamente através do BIOS
- lspci – exibe os dispositivos PCI vistos pela CVM.
- ID do disco órfão
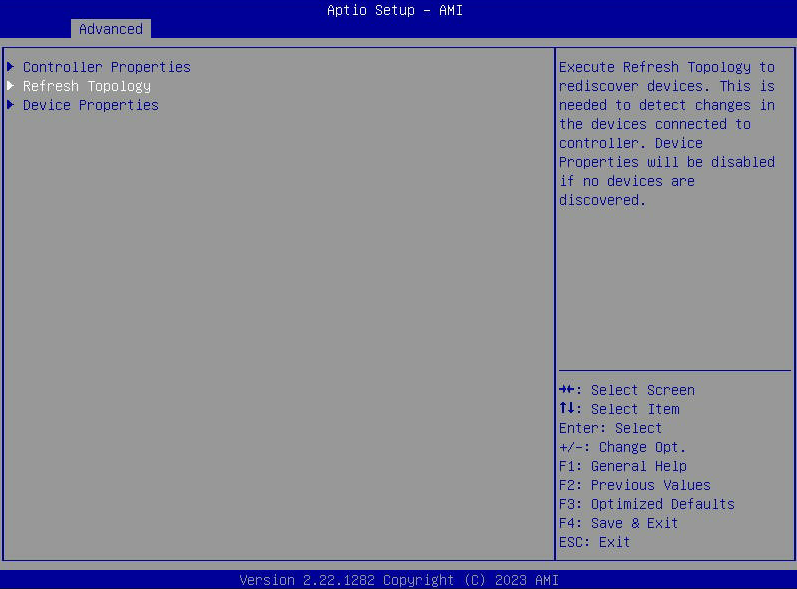
- Se a opção "Propriedades do dispositivo" estiver esmaecida, selecione "Atualizar topologia".
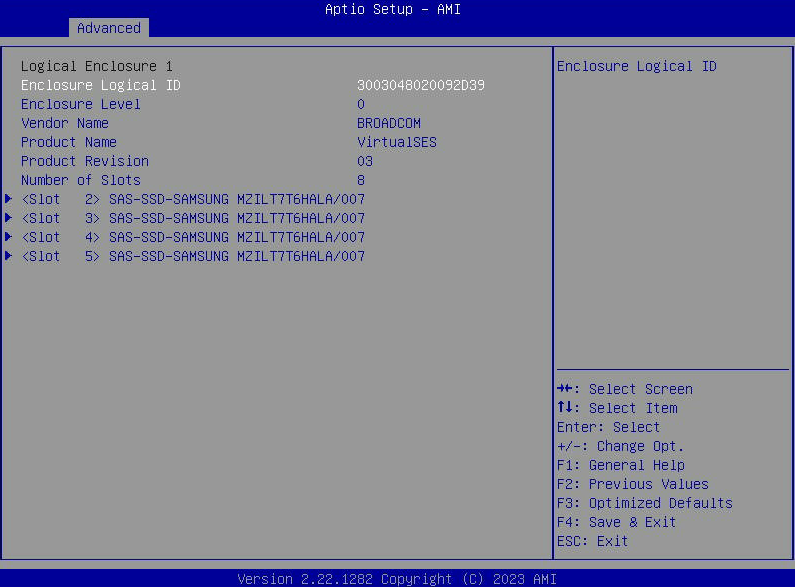
- Selecione “Propriedades da unidade” para ver uma lista de unidades SATA visíveis para o host.
- G6 e G7: Como habilitar e acessar LSI HBA OPROM
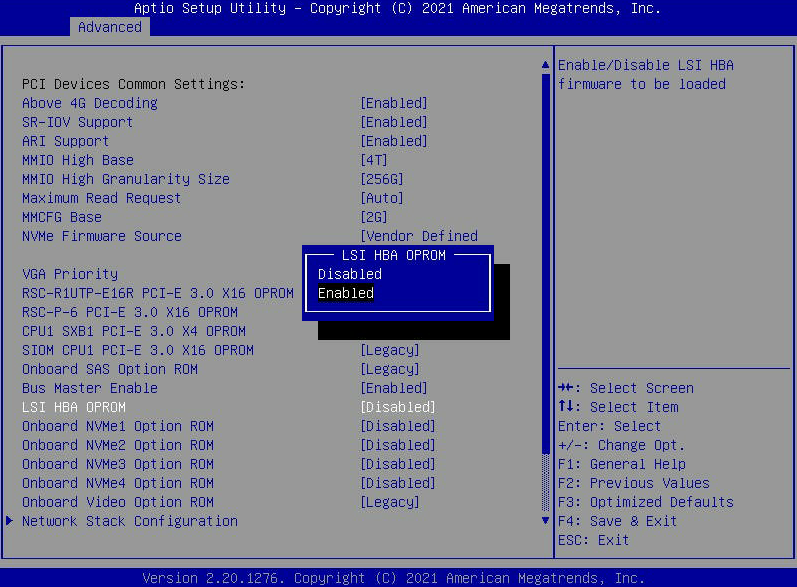
- Entre no menu BIOS pressionando a tecla DEL na tela inicial “Nutanix” enquanto o nó está inicializando.
- Vá para a guia "Avançado" e encontre "LSI HBA OPROM". Defina isso como "Ativado". Em seguida, pressione “F4” para “Salvar e sair” do menu BIOS . Isso fará com que o nó seja reinicializado.
- Nota: Depois de obter as informações necessárias, volte ao BIOS e DESATIVE o OPROM. Você também pode pressionar F3 para carregar padrões otimizados, o que trará o BIOS de volta às configurações originais de fábrica, onde o OPROM está desabilitado.
- Na próxima inicialização, procure a tela intitulada "Avago Technologies MPT SAS3 BIOS " e pressione CRTL+C para entrar no "SAS Configuration Utility".
- Uma vez dentro do Config Utility, selecione a placa HBA de seu interesse. Os modelos de vários nós (2U4N, 2U2N) terão no máximo uma placa HBA, enquanto as plataformas de nó único (2U1N) podem ter até três. Em sistemas multi-HBA, cada HBA atenderá um subconjunto diferente de unidades em cada nó.
- Na próxima tela, selecione "SAS Topology" e depois "Direct Attach Devices" para ver informações sobre as unidades associadas a esse HBA.
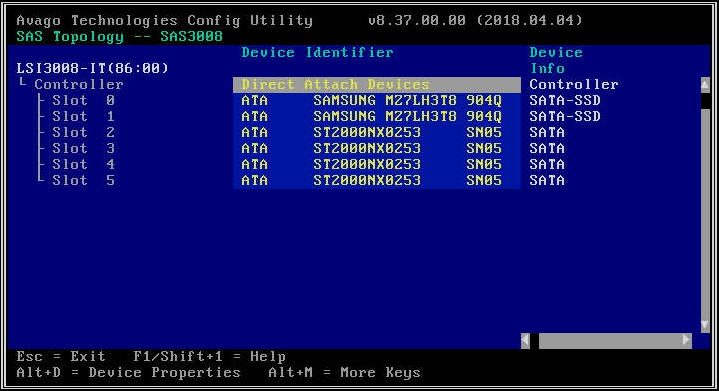
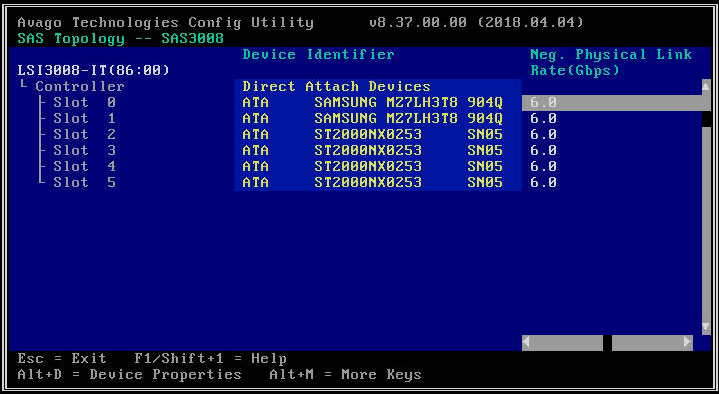
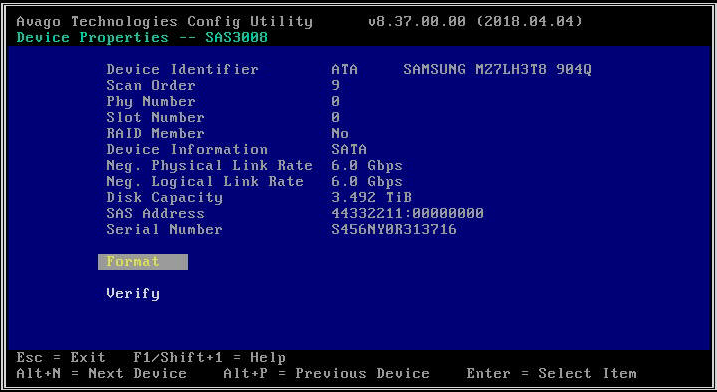
- Se o HBA selecionado não detectar nenhuma unidade, ele informará "Nenhum dispositivo para exibir".
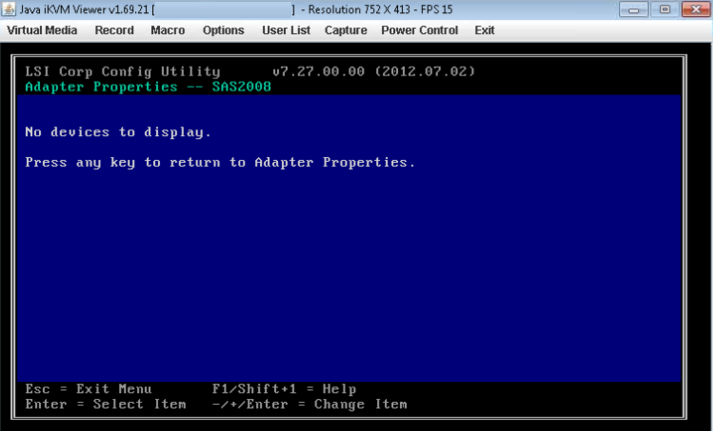
- Pode haver um caso em que o disco esteja DOWN em lsiutil , geralmente após uma substituição ou atualização dos discos. Quando todas as verificações acima forem realizadas e o disco ainda não estiver visível, compare o disco antigo e o novo "caixa ou bandeja de disco". Certifique-se de que o tipo seja o mesmo. Pode haver casos em que um tipo de disco incorreto é despachado e ele não se encaixa corretamente no compartimento de disco e, portanto, não é detectado pelo controlador.

- Identifique o tipo de nó ou o nó problemático.
Execute ncli host ls e encontre o ID do nó correspondente. A localização específica do slot do nó, a série do nó e o tipo de nó são informações importantes a serem documentadas em caso de problemas recorrentes. Também ajuda a rastrear os problemas de campo com HBAs, localizações de nós e tipos de nós. - Identifique a ocorrência da falha.
- Verifique o registro do Stargate. O log stargate.INFO do período correspondente indica se o Stargate viu um problema com um disco e o enviou ao Disk Manager (Hades) para ser verificado ou se houve outros erros ao acessar o disco. Use o número de ID do disco e o número de série para obter o grep no log do Stargate no nó correspondente em que o disco está.
- O log do Hades contém informações sobre os discos que ele vê e a integridade dos discos. Ele também verifica qual disco é de metadados ou disco curador e seleciona um se ainda não existir no sistema ou tiver sido removido/desaparecido do sistema. Verifique o registro do Hades.
- Verifique df -h em /home/nutanix/data/logs/sysstats/df.INFO para ver quando o disco foi visto pela última vez como montado.
- Verifique /home/nutanix/data/logs/sysstats/iostat.INFO para ver quando o dispositivo foi visto pela última vez.
- Verifique /home/log/messages em busca de erros no dispositivo, especificamente usando o nome do dispositivo, por exemplo, sda ou sdc.
- Verifique o dmesg em busca de erros no controlador ou dispositivo. Execute dmesg | less para as mensagens atuais no anel ou observe a saída dmesg registrada em /var/log .
- Identifique a causa da falha do disco.
- Verifique quando o CVM foi iniciado pela última vez se os últimos dados de utilização do disco não estavam disponíveis. Novamente, faça referência aos registros do Stargate e do Hades.
- Verifique o log do Stargate no momento da falha do disco. Stargate envia um disco para Hades para verificar se ele não responde em um determinado tempo e tempo limite de operações nesse disco. Erros e versões diferentes representam isso de maneira diferente, portanto, sempre pesquise por ID de disco e serial de disco.
- Verifique a contagem de falhas no disco.
Se uma unidade falhar mais de uma vez neste slot e o disco for substituído, isso indicará um possível problema no chassi naquele momento. - Verifique se o lsiutil está mostrando erros.
Se lsiutil mostrar erros uniformemente em vários slots, isso pode indicar um controlador defeituoso. - Verifique se há problemas conhecidos com o FW da unidade em busca de erros de disco.
- Se este for um G8, a versão do MCU é 1.1A ou superior e os Backplanes também foram atualizados:
Consulte este documento: NX-G8: Nutanix Backplane CPLD, placa-mãe CPLD e guia de atualização manual do firmware Multinode EC . - Se este for um G8, verifique se o FW do controlador LSI é 25.00.00 ou superior:
Existem correções relacionadas à estabilidade do SSD quando o trim está em uso que corrige uma instância que causa erros de PHY nas unidades e instabilidade. Também é importante do ponto de vista de solução de problemas estar no FW 25.00.00 ou superior.
Observação: ID do evento: 191 , G-Sense_Error_Rate na saída " smartctl " para HDDs da Seagate pode ser ignorado com segurança, a menos que haja degradação de desempenho. O valor G-Sense_Error_Rate indica apenas a adaptação do HDD à detecção de choque ou vibração. A Seagate recomenda não confiar nesses valores, pois esse contador altera dinamicamente o limite durante o tempo de execução.
Artigos relacionados
- Artigo original no Portal Nutanix: Artigo Nutanix KB: 1113
- Página inicial da Nutanix
