Solución de problemas de HDD, SSD y HBA
Solución de problemas de HDD, SSD y HBA
Solución de problemas de HDD, SSD y HBA
Descripción
Cuando una unidad experimenta errores recuperables, advertencias o una falla total, el servicio Stargate marca el disco como fuera de línea. Si se detecta que el disco está fuera de línea 3 veces en una hora, se elimina del clúster automáticamente y se genera una alerta ( KB-4158 o KB-6287 ).
Si se genera una alerta en Prism, se debe reemplazar el disco. No es necesario realizar pasos para la solución de problemas.
NOTA: Si se encuentra un disco fallido en Nutanix Clusters en AWS, una vez que se confirme que el disco falló, proceda a condenar el nodo respectivo. Condenar el nodo afectado lo reemplazará con una nueva instancia básica del mismo tipo.
Solución
Una vez que se reemplaza el disco, se debe realizar una verificación del estado del NCC para garantizar el estado óptimo del clúster.
Sin embargo, si no se generó una alerta en primer lugar o se requiere un análisis más detallado, se pueden seguir los pasos a continuación para solucionar el problema.
Antes de comenzar a solucionar problemas, verifique el tipo de controlador HBA.
Precaución:
El uso del comando SAS3IRCU contra un HBA LSI 3408 o superior puede provocar eventos NMI que podrían provocar que el almacenamiento no esté disponible.
Confirme el controlador HBA antes de usar los siguientes comandos.
Para determinar qué tipo de HBA se utiliza, busque el nombre del controlador ubicado en /etc/nutanix/hardware_config.json en el CVM .
- Ejemplo de resultado cuando se utiliza SAS3008:
En este caso, el comando SAS3IRCU es el comando correcto a utilizar.
Tenga en cuenta la línea "led_address": "sas3ircu:0,1:0" :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Ejemplo del resultado cuando se utiliza SAS3400/3800 (o más reciente):
En este caso, no sería aconsejable utilizar SAS3IRCU. Utilice el comando storcli en su lugar. Para obtener información sobre StorCLI, consulte KB-10951 .
Nota "led_address": línea "storcli:0" .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Identificar los discos problemáticos
- Verifique la consola web de Prism para ver si hay un disco fallido. En la vista de diagrama, puede ver el disco faltante en rojo o gris.
- Verifique la consola web de Prism para ver las alertas de disco o use el siguiente comando para verificar los discos que generan mensajes de error.
nutanix@cvm$ ncli alert ls - Compruebe si a algún nodo le faltan discos montados. Las dos salidas deben coincidir numéricamente.
- Verifique los discos que están montados en el CVM (Controlador VM).
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Verifique los discos que están físicos en el CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Compruebe si el estado de todos los discos es En línea y está indicado como Normal .
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Verifique los discos que están montados en el CVM (Controlador VM).
- Valide la cantidad esperada de discos en el clúster.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lEl resultado del comando anterior debe ser la suma de los resultados de los pasos 1c.i y 1c.ii.
Hay casos en los que el número puede ser mayor o menor de lo esperado. Por lo tanto, es una métrica importante que se puede comparar con los discos enumerados en el paso 1b.
- Busque discos adicionales o faltantes.
nutanix@cvm$ ncli disk ls - Verifique que todos los discos estén indicados como rw montado (lectura-escritura) y no ro (solo lectura).
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Identificar los problemas con los nodos de los discos.
- ID de disco huérfano
Esta es una identificación de disco que los sistemas ya no usan pero que no se eliminó correctamente. Los síntomas incluyen ver una ID de disco adicional en la salida de ncli disk ls .
Para corregir la ID del disco huérfano:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueAsegúrese de validar el número de serie del disco y de que el dispositivo no esté en el sistema. Además, asegúrese de que todos los discos se estén llenando usando lsscsi , mount , df -h y contando los discos para completar la ocupación del disco.
- Disco fallido y/o disco faltante
Compruebe si el disco es visible para el controlador, ya que es el dispositivo en cuyo bus reside el disco. Se pueden utilizar los siguientes comandos:
- lspci : muestra los dispositivos PCI vistos por el CVM.
- Dispositivo NVME - Controlador de memoria no volátil: Intel Corporation PCIe Data Center SSD (rev 01).
- Controlador SAS3008 - Controlador SCSI conectado en serie: LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) - LSI.
- Controlador SAS2308 (Dell) - Controlador SCSI conectado en serie: LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (rev 05).
- MegaRaid LSI 3108 (Dell) - Controlador de bus RAID: LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader] (rev 02).
- LSI SAS3108 (UCS) - Controlador SCSI conectado en serie: LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (rev 02).
- lsiutil : muestra la perspectiva de las tarjetas HBA (adaptador de bus de host) de los puertos y si los puertos están en estado UP. Si un puerto no está activo, el dispositivo no respondió o el puerto o la conexión al dispositivo están defectuosos. El problema más probable es el dispositivo (disco).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi : enumera los dispositivos de bus SCSI vistos que incluyen cualquier HDD o SSD (excepto NVME, que no pasa por el controlador SATA).
- sas3ircu : informa la posición de la ranura y el estado del disco. Es útil para discos faltantes o para verificar que los discos estén en la ranura correcta. (NO ejecute el siguiente comando en el hardware Lenovo HX, ya que puede provocar bloqueos y restablecimientos de HBA)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli : informa errores de unidad similares a lsiutil. También informa la posición de la ranura y el estado del disco.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Verifique el dmesg del CVM para ver si hay mensajes LSI mpt3sas. Normalmente deberíamos ver una entrada para cada ranura física. ( El siguiente ejemplo muestra que la dirección SAS "0x5000c5007286a3f5" se verifica repetidamente debido a un disco defectuoso o fallido. Observe cómo las otras direcciones se detectan una vez y el sospechoso se sondea repetidamente).
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl : si Hades indica que smartctl verifica un disco 3 veces en una hora, falla automáticamente.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- Consulte KB-8094 para solucionar problemas con smartctl .
- Verifique si hay discos fuera de línea usando NCC check disk_online_check .
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Consulte KB 1536 para obtener más información sobre la solución de problemas de discos sin conexión.
- Confirme si los discos se ven desde LSI Config Utility. Esto puede resultar útil para descartar posibles problemas de configuración driver o CVM/hipervisor que podrían impedirle detectar determinadas unidades. La utilidad de configuración LSI le brinda una interfaz directa al firmware del HBA sin depender de un sistema operativo de software. Se puede usar para hacer muchas de las mismas cosas que puede hacer con "lsiutil": (a) verificar si se detecta un disco en una ranura en particular, (b) verificar la velocidad del enlace del disco, (c) activar una baliza LED en una unidad en particular. En las plataformas G6 y G7, el menú de configuración LSI está deshabilitado de forma predeterminada, por lo que debe habilitarlo en el BIOS antes de poder usarlo. En las plataformas G8, debe ver las unidades conectadas directamente a través del menú BIOS .
- G8: vea las unidades conectadas directamente a través del BIOS
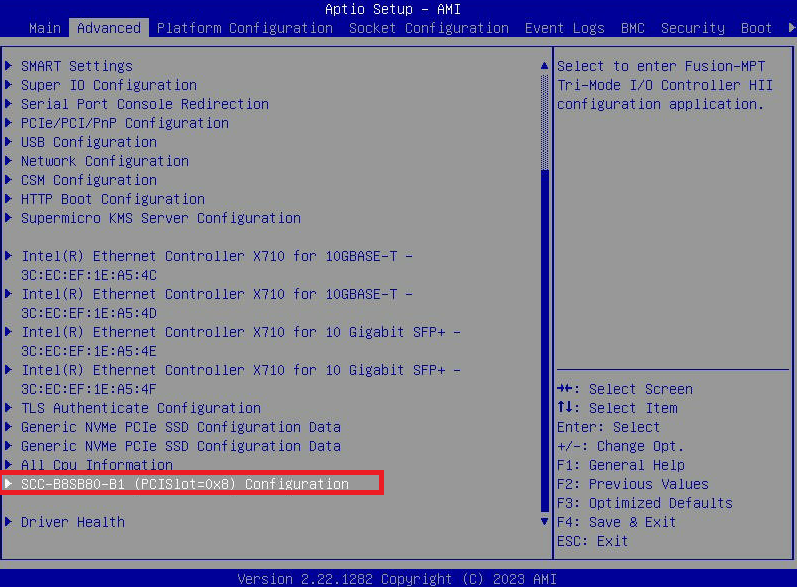
- Ingrese al menú BIOS presionando la tecla SUPR en la pantalla de inicio de "Nutanix" mientras el nodo se está iniciando.
- Vaya a la pestaña " Avanzado " y seleccione " Configuración SCC-B8SB80-B1 (PCISlot=0x8) ". Así se llama la opción de menú en 3060-G8. Es posible que tenga un nombre ligeramente diferente en otros modelos.
- G8: vea las unidades conectadas directamente a través del BIOS
- lspci : muestra los dispositivos PCI vistos por el CVM.
- ID de disco huérfano
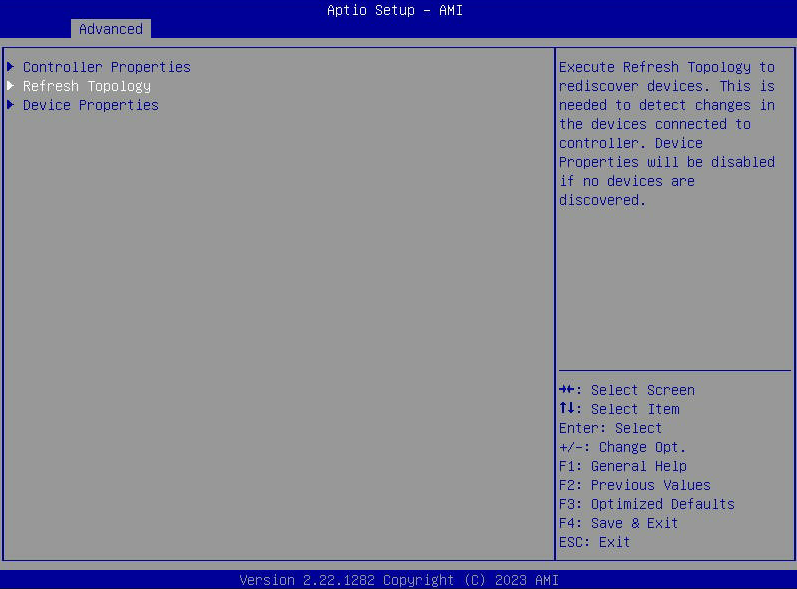
- Si la opción "Propiedades del dispositivo" está atenuada, seleccione "Actualizar topología".
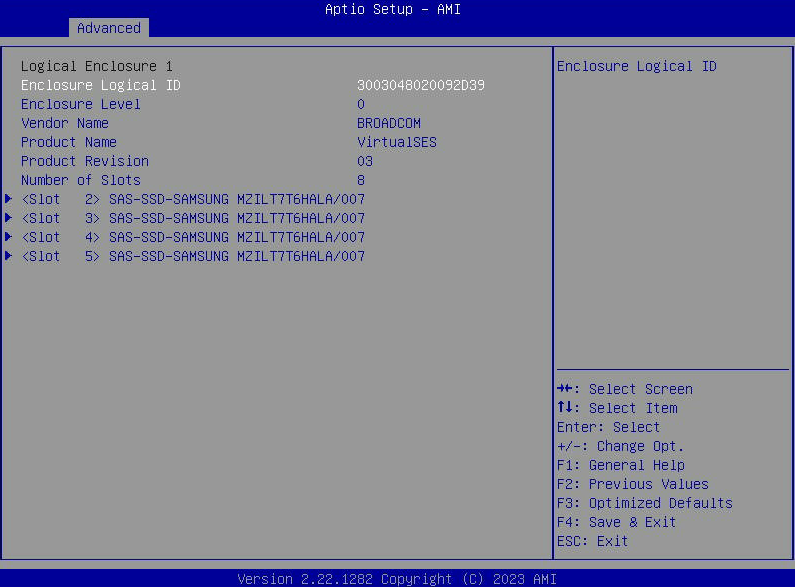
- Seleccione "Propiedades de la unidad" para ver una lista de las unidades SATA visibles para el host.
- G6 y G7: Cómo habilitar y acceder a LSI HBA OPROM
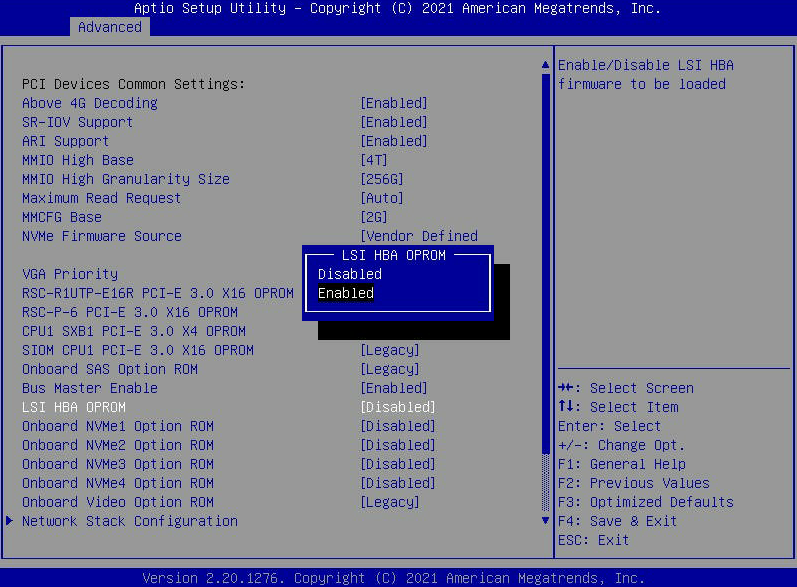
- Ingrese al menú BIOS presionando la tecla SUPR en la pantalla de inicio de "Nutanix" mientras el nodo se está iniciando.
- Vaya a la pestaña "Avanzado" y busque "LSI HBA OPROM". Establezca esto en "Habilitado". Luego presione "F4" para "Guardar y salir" del menú BIOS . Esto hará que el nodo se reinicie.
- Nota: Una vez que haya obtenido la información que necesita, asegúrese de volver al BIOS y DESACTIVAR la OPROM. También puede presionar F3 para cargar los valores predeterminados optimizados, lo que devolverá el BIOS a su configuración original de fábrica donde la OPROM está deshabilitada.
- En el siguiente inicio, busque la pantalla titulada "Avago Technologies MPT SAS3 BIOS " y presione CRTL+C para ingresar a la "Utilidad de configuración SAS".
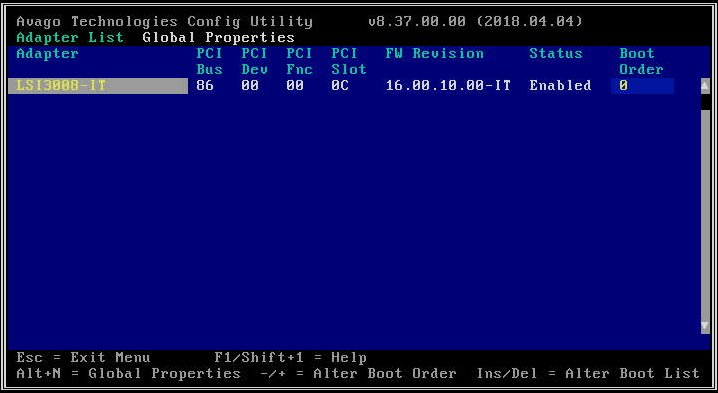
- Una vez dentro de Config Utility, seleccione la tarjeta HBA que le interese. Los modelos de múltiples nodos (2U4N, 2U2N) solo tendrán un máximo de una tarjeta HBA, mientras que las plataformas de un solo nodo (2U1N) pueden tener hasta tres. En sistemas de múltiples HBA, cada HBA prestará servicio a un subconjunto diferente de unidades en cada nodo.
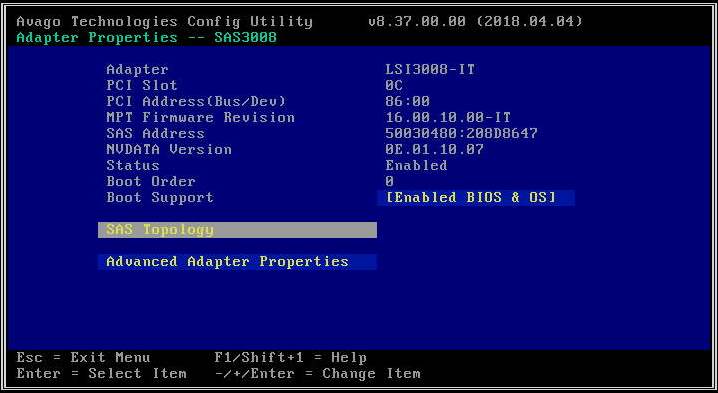
- En la siguiente pantalla, seleccione "Topología SAS" y luego "Dispositivos de conexión directa" para ver información sobre las unidades asociadas con ese HBA.
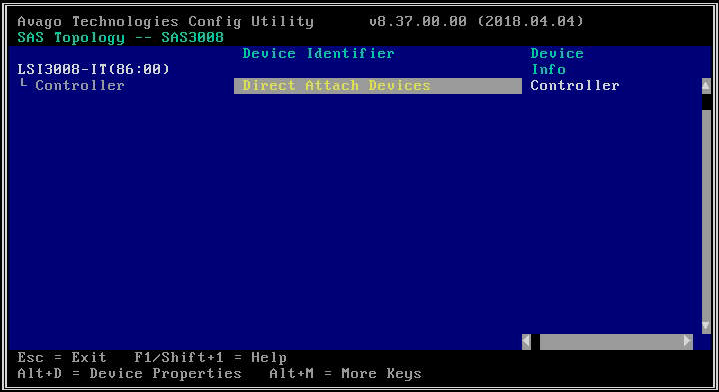
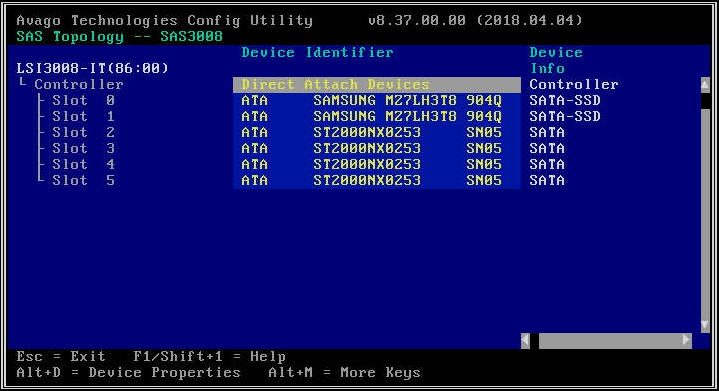
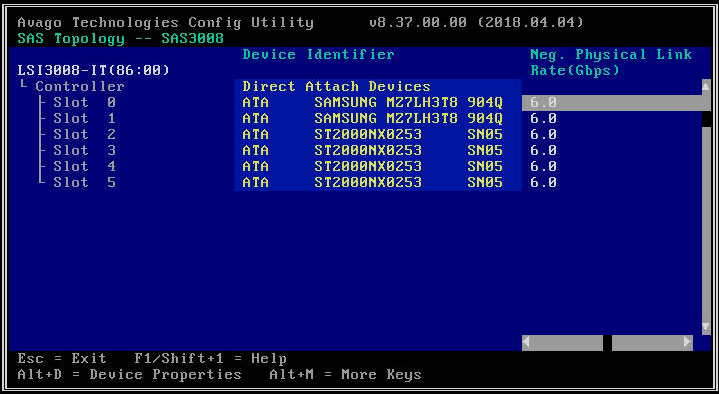
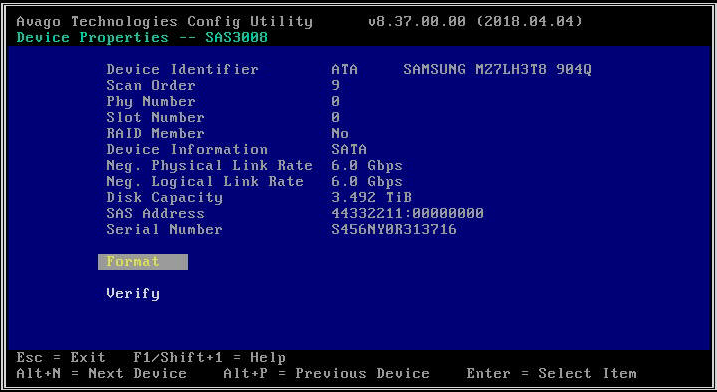
- Si el HBA que seleccionó no detecta ninguna unidad, informará "No hay dispositivos para mostrar".
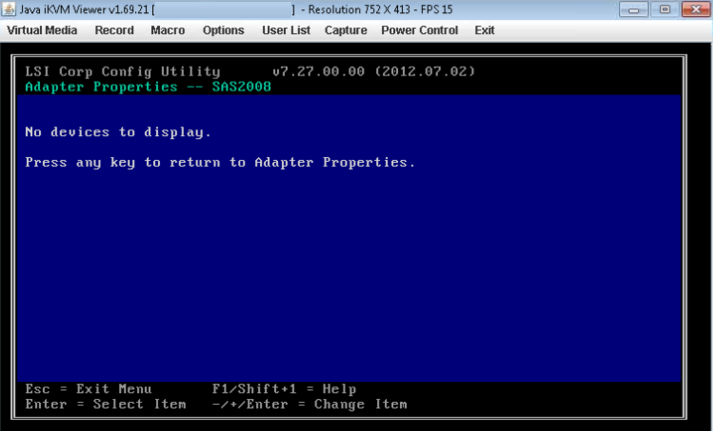
- Puede darse el caso de que el disco esté CAIDO en lsiutil , generalmente después de un reemplazo o una actualización de los discos. Cuando se hayan realizado todas las comprobaciones anteriores y el disco aún no esté visible, compare el "caddy o bandeja de disco" del disco antiguo y el nuevo. Asegúrese de que el tipo sea el mismo. Puede haber casos en los que se envíe un tipo de disco incorrecto y no se asiente correctamente en el compartimiento del disco, por lo que el controlador no lo detecta.

- Identifique el tipo de nodo o el nodo problemático.
Ejecute ncli host ls y busque el ID del nodo coincidente. La ubicación específica de la ranura del nodo, el número de serie y el tipo de nodo son información importante que se debe documentar en caso de problemas recurrentes. También ayuda a realizar un seguimiento de los problemas de campo con los HBA, las ubicaciones de los nodos y los tipos de nodos. - Identificar la ocurrencia de la falla.
- Consulta el registro de Stargate. El registro stargate.INFO para el período correspondiente indica si Stargate vio un problema con un disco y lo envió al Administrador de discos (Hades) para que lo verificara o si tuvo otros errores al acceder al disco. Utilice el número de identificación del disco y el número de serie para buscar en el registro de Stargate en el nodo correspondiente en el que se encuentra el disco.
- El registro de Hades contiene información sobre los discos que ve y el estado de los discos. También verifica qué disco es de metadatos o disco Curator y selecciona uno si aún no existía en el sistema o si fue eliminado/desaparecido del sistema. Consulta el registro de Hades.
- Verifique df -h en / home/nutanix/data/logs/sysstats/df.INFO para ver cuándo se vio el disco montado por última vez.
- Consulte /home/nutanix/data/logs/sysstats/iostat.INFO para ver cuándo se vio el dispositivo por última vez.
- Verifique /home/log/messages para ver si hay errores en el dispositivo, específicamente usando el nombre del dispositivo, por ejemplo, sda o sdc.
- Verifique dmesg para detectar errores en el controlador o dispositivo. Ejecute dmesg | less para los mensajes actuales en el anillo, o mire la salida dmesg registrada en /var/log .
- Identifique la causa del fallo del disco.
- Compruebe cuándo se inició el CVM por última vez si los últimos datos de uso del disco no estaban disponibles. Nuevamente, haga referencia a los registros de Stargate y Hades.
- Verifique el registro de Stargate en el momento de la falla del disco. Stargate envía un disco a Hades para verificar si no responde en un tiempo determinado y desactiva el tiempo de espera de ese disco. Los diferentes errores y versiones lo representan de manera diferente, por lo que siempre busque por ID de disco y serie de disco.
- Verifique el recuento de fallas del disco.
Si una unidad falla más de una vez en esta ranura y se reemplaza el disco, indicaría un posible problema con el chasis en ese punto. - Compruebe si lsiutil muestra errores.
Si lsiutil muestra errores de manera uniforme en varias ranuras, puede indicar un controlador defectuoso. - Verifique si hay problemas conocidos con el FW de la unidad para detectar errores de disco.
- Si se trata de un G8, la versión de MCU es 1.1A o superior y los Backplanes también se actualizaron:
Consulte este documento: NX-G8: Guía de actualización manual del firmware Nutanix Backplane CPLD, placa base CPLD y Multinode EC . - Si se trata de un G8, verifique que el FW del controlador LSI sea 25.00.00 o superior:
Hay correcciones relacionadas con la estabilidad de SSD cuando se usa el recorte que corrigen una instancia que causa que se vean errores de PHY en las unidades e inestabilidad. También es importante desde el punto de vista de la resolución de problemas tener el FW 25.00.00 o superior.
Nota: ID de evento: 191 , G-Sense_Error_Rate en la salida " smartctl " para discos duros de Seagate se puede ignorar de forma segura a menos que haya una degradación del rendimiento. El valor G-Sense_Error_Rate solo indica que el disco duro se adapta a la detección de golpes o vibraciones. Seagate recomienda no confiar en estos valores ya que este contador cambia dinámicamente el umbral durante el tiempo de ejecución.
Artículos relacionados
- Artículo original en Nutanix Portal: Artículo de Nutanix KB: 1113
- Página de inicio de Nutanix
