Fehlerbehebung bei Festplattenlaufwerken, SSDs und HBAs
Fehlerbehebung bei Festplattenlaufwerken, SSDs und HBAs
Fehlerbehebung bei Festplattenlaufwerken, SSDs und HBAs
Beschreibung
Wenn bei einem Laufwerk behebbare Fehler, Warnungen oder ein kompletter Ausfall auftreten, markiert der Stargate-Dienst die Festplatte als offline. Wenn die Festplatte innerhalb einer Stunde dreimal als offline erkannt wird, wird sie automatisch aus dem Cluster entfernt und eine Warnung generiert ( KB-4158 oder KB-6287 ).
Wenn in Prism eine Warnung generiert wird, muss die Festplatte ausgetauscht werden. Schritte zur Fehlerbehebung müssen nicht ausgeführt werden.
HINWEIS: Wenn in einem Nutanix-Cluster auf AWS eine ausgefallene Festplatte gefunden wird, können Sie den entsprechenden Knoten deaktivieren, sobald der Festplattenfehler bestätigt wurde. Durch die Deaktivierung des betroffenen Knotens wird dieser durch eine neue Bare-Metal-Instanz desselben Typs ersetzt.
Lösung
Nach dem Austausch der Festplatte sollte eine NCC-Integritätsprüfung durchgeführt werden, um eine optimale Cluster-Integrität sicherzustellen.
Wenn jedoch zunächst keine Warnung generiert wurde oder eine weitere Analyse erforderlich ist, können die folgenden Schritte zur weiteren Fehlerbehebung verwendet werden.
Bevor Sie mit der Fehlerbehebung beginnen, überprüfen Sie den Typ des HBA-Controllers.
Vorsicht:
Die Verwendung des Befehls SAS3IRCU bei einem HBA vom Typ LSI 3408 oder höher kann zu NMI-Ereignissen führen, die eine Nichtverfügbarkeit des Speichers zur Folge haben können.
Bestätigen Sie den HBA-Controller, bevor Sie die folgenden Befehle verwenden.
Um zu bestimmen, welcher HBA-Typ verwendet wird, suchen Sie auf dem CVM nach dem Controllernamen in /etc/nutanix/hardware_config.json.
- Beispiel der Ausgabe bei Verwendung von SAS3008:
In diesem Fall ist der Befehl SAS3IRCU der richtige Befehl.
Beachten Sie die Zeile „led_address“: „sas3ircu:0,1:0“ :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Beispiel der Ausgabe bei Verwendung von SAS3400/3800 (oder neuer):
In diesem Fall wäre die Verwendung von SAS3IRCU nicht ratsam. Verwenden Sie stattdessen den Befehl storcli . Informationen zu StorCLI finden Sie in KB-10951 .
Beachten Sie die Zeile „led_address“: „storcli:0“ .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Identifizieren Sie die problematischen Datenträger
- Suchen Sie in der Prism-Webkonsole nach der ausgefallenen Festplatte. In der Diagrammansicht wird die fehlende Festplatte rot oder grau angezeigt.
- Suchen Sie in der Prism-Webkonsole nach Festplattenwarnungen oder verwenden Sie den folgenden Befehl, um nach Festplatten zu suchen, die Fehlermeldungen generieren.
nutanix@cvm$ ncli alert ls - Überprüfen Sie, ob bei Knoten bereitgestellte Datenträger fehlen. Die beiden Ausgaben sollten numerisch übereinstimmen.
- Überprüfen Sie die Festplatten, die auf der CVM (Controller-VM) gemountet sind.
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Überprüfen Sie die physischen Datenträger im CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Überprüfen Sie, ob der Status aller Datenträger „ Online“ lautet und als „Normal“ angezeigt wird.
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Überprüfen Sie die Festplatten, die auf der CVM (Controller-VM) gemountet sind.
- Überprüfen Sie die erwartete Anzahl von Datenträgern im Cluster.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lDie Ausgabe des obigen Befehls sollte die Summe der Ausgaben der Schritte 1c.i und 1c.ii sein.
Es gibt Fälle, in denen die Zahl höher oder niedriger als erwartet sein kann. Es handelt sich also um eine wichtige Kennzahl, die mit den in Schritt 1b aufgelisteten Datenträgern verglichen werden kann.
- Suchen Sie nach zusätzlichen oder fehlenden Datenträgern.
nutanix@cvm$ ncli disk ls - Überprüfen Sie, ob alle Datenträger als gemountete RW (Lesen/Schreiben) und nicht als RO (Nur-Lesen) gekennzeichnet sind.
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Identifizieren Sie die Probleme mit den Datenträgerknoten
- Verwaiste Datenträger-ID
Dies ist eine Datenträger-ID, die die Systeme nicht mehr verwenden, die aber nicht ordnungsgemäß entfernt wurde. Zu den Symptomen gehört, dass in der Ausgabe von ncli disk ls eine zusätzliche Datenträger-ID aufgeführt wird.
So beheben Sie die verwaiste Datenträger-ID:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueStellen Sie sicher, dass Sie die Seriennummer der Festplatte validieren und dass sich das Gerät nicht im System befindet. Stellen Sie außerdem sicher, dass alle Festplatten mit lsscsi , mount , df -h gefüllt sind und zählen Sie die Festplatten für die vollständige Festplattenbestückung.
- Fehlerhafte Festplatte und/oder fehlende Festplatte
Überprüfen Sie, ob die Festplatte für den Controller sichtbar ist, da es sich um das Gerät handelt, auf dessen Bus sich die Festplatte befindet. Die folgenden Befehle können verwendet werden:
- lspci – zeigt die vom CVM erkannten PCI-Geräte an.
- NVME-Gerät – Nichtflüchtiger Speichercontroller: Intel Corporation PCIe Data Center SSD (Rev. 01).
- SAS3008-Controller – Serial Attached SCSI-Controller: LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (Rev. 02) – LSI.
- SAS2308-Controller (Dell) – Serial Attached SCSI-Controller: LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (Rev. 05).
- MegaRaid LSI 3108 (Dell) – RAID-Bus-Controller: LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader] (Rev. 02).
- LSI SAS3108 (UCS) – Serial Attached SCSI-Controller: LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (Rev. 02).
- lsiutil - zeigt die HBA-Kartenperspektive (Host Bus Adapter) der Ports an und ob die Ports im Status „UP“ sind. Wenn ein Port nicht aktiv ist, hat das Gerät entweder nicht geantwortet oder der Port bzw. die Verbindung zum Gerät ist fehlerhaft. Das wahrscheinlichste Problem liegt beim Gerät (Festplatte).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi – listet die angezeigten SCSI-Busgeräte auf, darunter alle HDDs oder SSDs (außer NVME, das nicht über den SATA-Controller läuft).
- sas3ircu – meldet Steckplatzposition und Festplattenstatus. Dies ist nützlich, wenn Festplatten fehlen oder wenn überprüft werden muss, ob sich Festplatten im richtigen Steckplatz befinden. (Führen Sie den folgenden Befehl NICHT auf Lenovo HX-Hardware aus, da dies zu HBA-Abstürzen und -Resets führen kann.)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli - Meldet Laufwerksfehler ähnlich wie lsiutil. Meldet auch Steckplatzposition und Festplattenstatus.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Überprüfen Sie das dmesg des CVM auf LSI mpt3sas-Meldungen. Normalerweise sollten wir einen Eintrag für jeden physischen Steckplatz sehen. ( Das folgende Beispiel zeigt, dass die SAS-Adresse „0x5000c5007286a3f5“ aufgrund einer fehlerhaften/ausgefallenen Festplatte wiederholt geprüft wird. Beachten Sie, dass die anderen Adressen einmal erkannt werden und die verdächtige Adresse wiederholt abgefragt wird. )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl – wenn Hades anzeigt, dass eine Festplatte innerhalb einer Stunde dreimal von smartctl geprüft wird, wird sie automatisch als fehlerhaft eingestuft.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- Informationen zur Fehlerbehebung mit smartctl finden Sie unter KB-8094 .
- Suchen Sie mit dem NCC-Check disk_online_check nach Offline-Festplatten.
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Weitere Informationen zur Fehlerbehebung bei Offlinedatenträgern finden Sie unter KB 1536 .
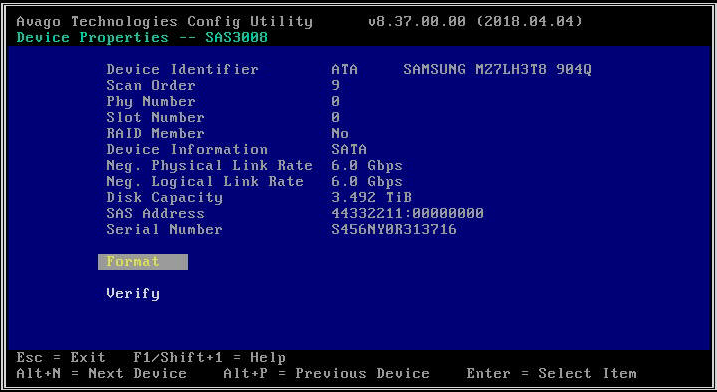
- Bestätigen Sie, ob Festplatten vom LSI Config Utility erkannt werden. Dies kann hilfreich sein, um mögliche driver oder CVM/Hypervisor-Konfigurationsprobleme auszuschließen, die verhindern könnten, dass Sie bestimmte Laufwerke erkennen. Das LSI Config Utility bietet Ihnen eine direkte Schnittstelle zur HBA-Firmware, ohne dass Sie auf ein Software-Betriebssystem angewiesen sind. Es kann für viele der gleichen Dinge verwendet werden, die Sie mit „lsiutil“ tun können: (a) Überprüfen, ob eine Festplatte in einem bestimmten Steckplatz erkannt wird, (b) Überprüfen der Festplattenverbindungsgeschwindigkeit, (c) Aktivieren einer LED-Anzeige auf einem bestimmten Laufwerk. Auf G6- und G7-Plattformen ist das LSI Config-Menü standardmäßig deaktiviert, sodass Sie es im BIOS aktivieren müssen, bevor Sie es verwenden können. Auf G8-Plattformen müssen Sie die angeschlossenen Laufwerke direkt über das BIOS Menü anzeigen.
- G8: Angeschlossene Laufwerke direkt über das BIOS anzeigen
- Rufen Sie das BIOS Menü auf, indem Sie beim Hochfahren des Knotens auf dem „Nutanix“-Begrüßungsbildschirm die ENTF-Taste drücken.
- Gehen Sie zur Registerkarte „ Erweitert “ und wählen Sie „ SCC-B8SB80-B1 (PCISlot=0x8) Konfiguration “. So heißt die Menüoption beim 3060-G8. Bei anderen Modellen kann sie etwas anders heißen.
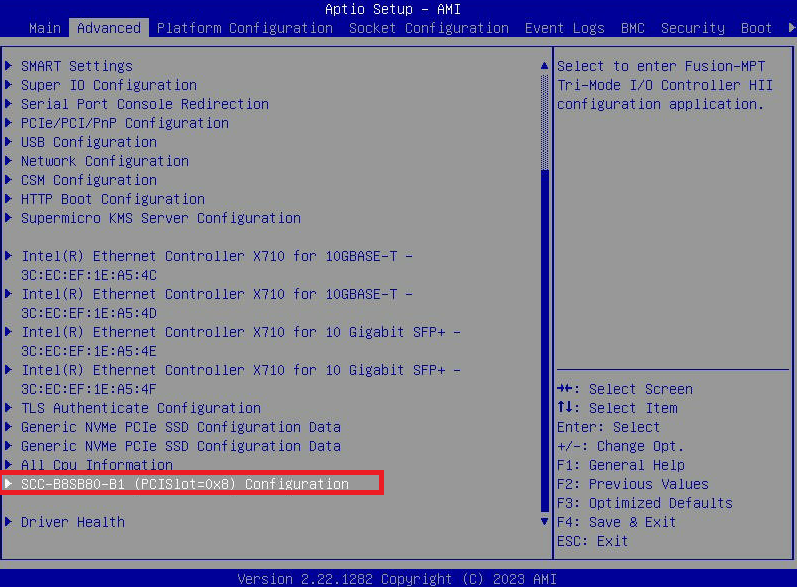
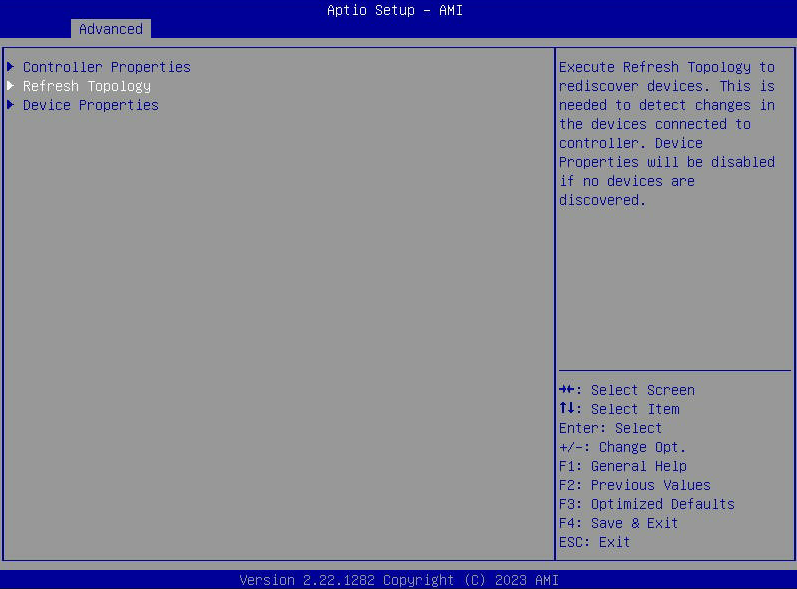
- G8: Angeschlossene Laufwerke direkt über das BIOS anzeigen
- lspci – zeigt die vom CVM erkannten PCI-Geräte an.
- Verwaiste Datenträger-ID
- Wenn die Option „Geräteeigenschaften“ ausgegraut ist, wählen Sie „Topologie aktualisieren“.
- Wählen Sie „Laufwerkseigenschaften“, um eine Liste der für den Host sichtbaren SATA-Laufwerke anzuzeigen.
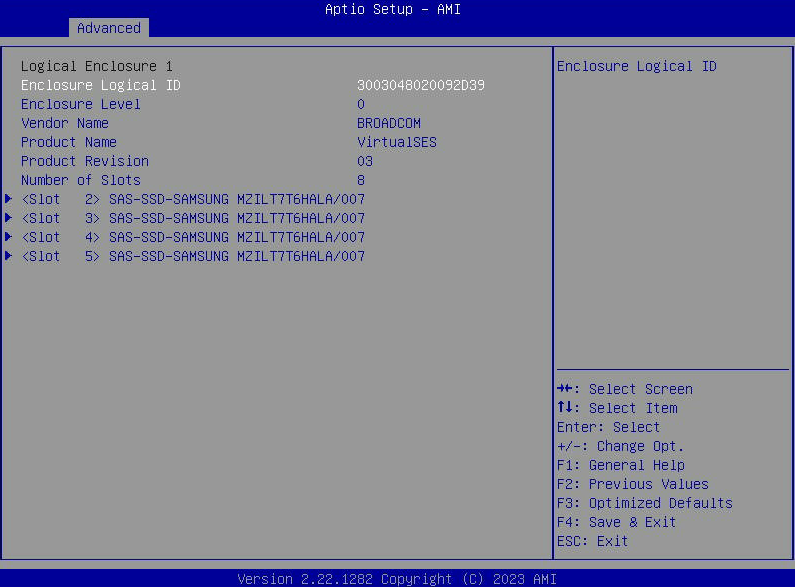
- G6 und G7: So aktivieren und greifen Sie auf LSI HBA OPROM zu
- Rufen Sie das BIOS Menü auf, indem Sie beim Hochfahren des Knotens auf dem „Nutanix“-Begrüßungsbildschirm die ENTF-Taste drücken.
- Gehen Sie zur Registerkarte „Erweitert“ und suchen Sie nach „LSI HBA OPROM“. Stellen Sie dies auf „Aktiviert“. Drücken Sie dann „F4“, um das BIOS Menü zu „Speichern und zu beenden“. Dadurch wird der Knoten neu gestartet.
- Hinweis: Nachdem Sie die benötigten Informationen erhalten haben, müssen Sie unbedingt zum BIOS zurückkehren und das OPROM DEAKTIVIEREN. Sie können auch F3 drücken, um die optimierten Standardeinstellungen zu laden. Dadurch wird das BIOS auf die ursprünglichen Werkseinstellungen zurückgesetzt, bei denen das OPROM deaktiviert ist.
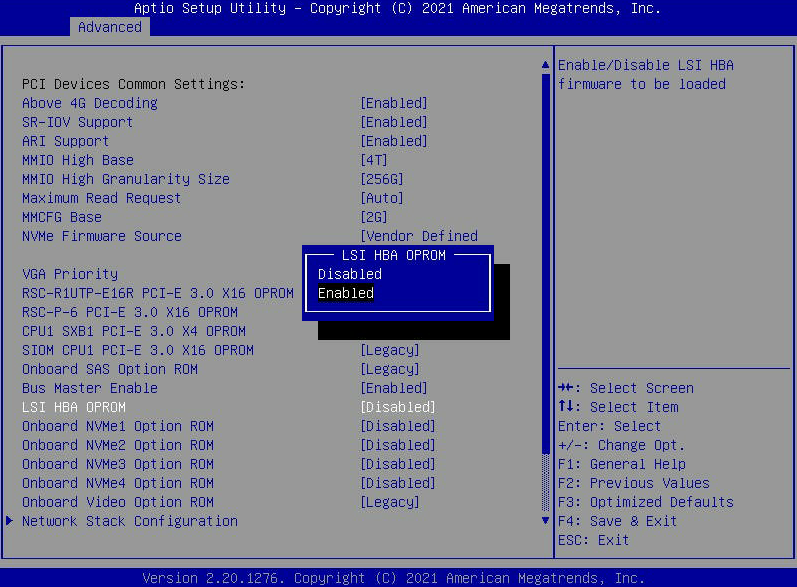
- Suchen Sie beim nächsten Start nach dem Bildschirm mit dem Titel „Avago Technologies MPT SAS3 BIOS “ und drücken Sie STRG+C, um das „SAS-Konfigurationsprogramm“ aufzurufen.
- Wählen Sie im Konfigurationsprogramm die gewünschte HBA-Karte aus. Multi-Node-Modelle (2U4N, 2U2N) verfügen nur über maximal eine HBA-Karte, während Single-Node-Plattformen (2U1N) bis zu drei haben können. In Multi-HBA-Systemen bedient jeder HBA eine andere Teilmenge von Laufwerken auf jedem Knoten.
- Wählen Sie auf dem nächsten Bildschirm „SAS-Topologie“ und dann „Direct Attach Devices“, um Informationen zu den mit diesem HBA verbundenen Laufwerken anzuzeigen.
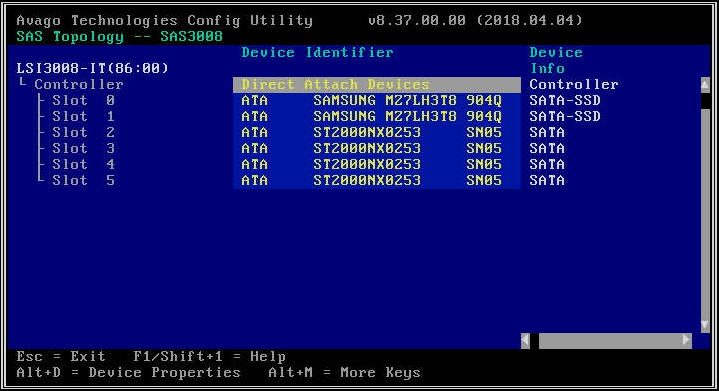
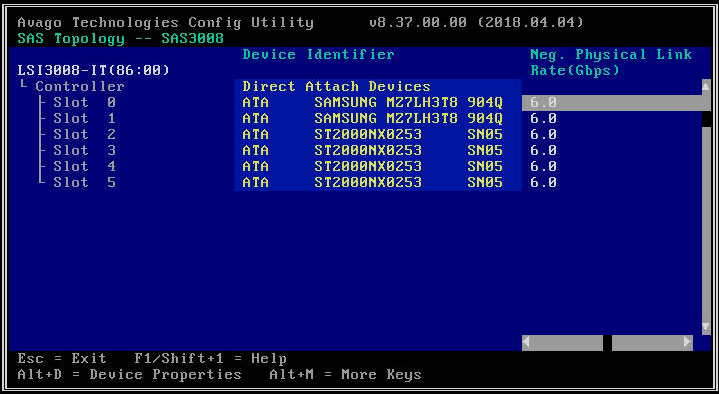
- Wenn der ausgewählte HBA überhaupt keine Laufwerke erkennt, wird die Meldung „Keine anzuzeigenden Geräte“ angezeigt.
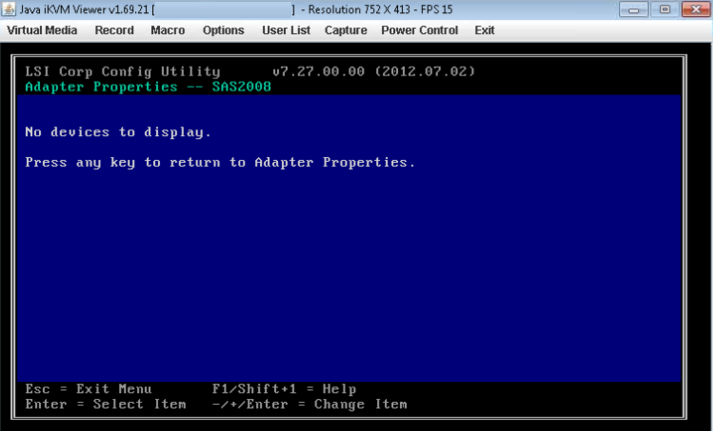
- Es kann vorkommen, dass die Festplatte in lsiutil DOWN ist, normalerweise nach einem Austausch oder Upgrade der Festplatten. Wenn alle oben genannten Prüfungen durchgeführt wurden und die Festplatte immer noch nicht sichtbar ist, vergleichen Sie den alten und den neuen Festplatten-"Festplatten-Caddy oder -Einschub". Stellen Sie sicher, dass der Typ derselbe ist. Es kann vorkommen, dass ein falscher Festplattentyp versendet wird und dieser nicht richtig im Festplattenschacht sitzt und daher vom Controller nicht erkannt wird.

- Identifizieren Sie den Knotentyp oder den problematischen Knoten.
Führen Sie ncli host ls aus und suchen Sie die passende Knoten-ID. Der spezifische Knotensteckplatzstandort, die Knotenseriennummer und der Knotentyp sind wichtige Informationen, die bei wiederkehrenden Problemen dokumentiert werden müssen. Dies hilft auch bei der Verfolgung der Feldprobleme mit den HBAs, Knotenstandorten und Knotentypen. - Identifizieren Sie das Fehlervorkommen.
- Überprüfen Sie das Stargate-Protokoll. Das stargate.INFO- Protokoll für den entsprechenden Zeitraum zeigt an, ob Stargate ein Problem mit einer Festplatte festgestellt und diese zur Überprüfung an den Disk Manager (Hades) gesendet hat oder ob beim Zugriff auf die Festplatte andere Fehler aufgetreten sind. Verwenden Sie die Festplatten-ID-Nummer und die Seriennummer, um im Stargate-Protokoll auf dem entsprechenden Knoten, in dem sich die Festplatte befindet, nachzusuchen.
- Das Hades-Protokoll enthält Informationen über die erkannten Datenträger und deren Zustand. Es prüft auch, welcher Datenträger ein Metadaten- oder Curator-Datenträger ist, und wählt einen aus, wenn noch keiner im System vorhanden war oder aus dem System entfernt wurde/verschwunden ist. Überprüfen Sie das Hades-Protokoll.
- Überprüfen Sie df -h in /home/nutanix/data/logs/sysstats/df.INFO , um zu sehen, wann die Festplatte zuletzt als gemountet angezeigt wurde.
- Überprüfen Sie /home/nutanix/data/logs/sysstats/iostat.INFO , um zu sehen, wann das Gerät zuletzt gesehen wurde.
- Suchen Sie in /home/log/messages nach Fehlern auf dem Gerät, insbesondere anhand des Gerätenamens, zum Beispiel sda oder sdc.
- Überprüfen Sie dmesg auf Fehler auf dem Controller oder Gerät. Führen Sie dmesg | less für die aktuellen Nachrichten im Ring aus oder sehen Sie sich die protokollierte dmesg-Ausgabe in /var/log an.
- Identifizieren Sie die Ursache für den Festplattenfehler.
- Überprüfen Sie, wann das CVM zuletzt gestartet wurde, wenn die letzten Nutzungsdaten der Festplatte nicht verfügbar waren. Sehen Sie sich auch hier die Stargate- und Hades-Protokolle an.
- Überprüfen Sie das Stargate-Protokoll zum Zeitpunkt des Festplattenfehlers. Stargate sendet eine Festplatte an Hades, um zu prüfen, ob sie innerhalb einer bestimmten Zeit nicht reagiert und ob bei dieser Festplatte ein Timeout auftritt. Verschiedene Fehler und Versionen stellen dies unterschiedlich dar, suchen Sie daher immer nach Festplatten-ID und Festplattenseriennummer.
- Überprüfen Sie die Anzahl der Festplattenfehler.
Wenn ein Laufwerk in diesem Steckplatz mehr als einmal ausgefallen ist und die Festplatte ersetzt wurde, deutet dies zu diesem Zeitpunkt auf ein potenzielles Gehäuseproblem hin. - Überprüfen Sie, ob lsiutil Fehler anzeigt.
Wenn lsiutil Fehler gleichmäßig auf mehreren Steckplätzen anzeigt, kann dies auf einen fehlerhaften Controller hinweisen. - Suchen Sie nach bekannten Problemen mit der Laufwerk-Firmware für die Festplattenfehler.
- Wenn es sich um ein G8 handelt, die MCU-Version 1.1A oder höher ist und die Backplanes ebenfalls aktualisiert wurden:
Verweisen Sie auf dieses Dokument: NX-G8: Handbuch zum manuellen Upgrade der Firmware für Nutanix Backplane CPLD, Motherboard CPLD und Multinode EC . - Wenn es sich um ein G8 handelt, überprüfen Sie, ob die Firmware des LSI-Controllers 25.00.00 oder höher ist:
Es gibt Fixes im Zusammenhang mit der SSD-Stabilität bei Verwendung von Trim, die eine Instanz korrigieren, die PHY-Fehler auf Laufwerken und Instabilität verursacht. Aus Sicht der Fehlerbehebung ist es auch wichtig, FW 25.00.00 oder höher zu verwenden.
Hinweis: Ereignis-ID: 191 , G-Sense_Error_Rate in der „ smartctl “-Ausgabe für Seagate-Festplatten kann ignoriert werden, sofern keine Leistungseinbußen auftreten. Der Wert G-Sense_Error_Rate zeigt nur an, dass sich die Festplatte an die Stoß- oder Vibrationserkennung anpasst. Seagate empfiehlt, diesen Werten nicht zu vertrauen, da dieser Indikator den Schwellenwert während der Laufzeit dynamisch ändert.
Verwandte Artikel
- Originalartikel im Nutanix-Portal: Nutanix KB-Artikel: 1113
- Nutanix-Landingpage
