Устранение неполадок HDD, SSD и HBA
Устранение неполадок HDD, SSD и HBA
Устранение неполадок HDD, SSD и HBA
Описание
Когда на диске возникают исправимые ошибки, предупреждения или полный сбой, служба Stargate помечает диск как отключенный. Если диск обнаруживается как отключенный 3 раза в течение часа, он автоматически удаляется из кластера и генерируется предупреждение ( KB-4158 или KB-6287 ).
Если в Prism генерируется предупреждение, диск необходимо заменить. Действия по устранению неполадок выполнять не нужно.
ПРИМЕЧАНИЕ. Если в кластерах Nutanix на AWS обнаружен неисправный диск, как только будет подтверждено, что диск неисправен, приступайте к блокировке соответствующего узла. При осуждении затронутого узла он будет заменен новым экземпляром того же типа, работающим без операционной системы.
Решение
После замены диска необходимо выполнить проверку работоспособности NCC, чтобы обеспечить оптимальное состояние кластера.
Однако если предупреждение не было создано изначально или требуется дальнейший анализ, для дальнейшего устранения неполадок можно использовать приведенные ниже шаги.
Прежде чем приступить к устранению неполадок, проверьте тип контроллера HBA.
Осторожность:
Использование команды SAS3IRCU для адаптера LSI 3408 или выше может вызвать события NMI, которые могут привести к недоступности хранилища.
Подтвердите контроллер HBA перед использованием следующих команд.
Чтобы определить , какой тип HBA используется, найдите имя контроллера, расположенное в файле /etc/nutanix/hardware_config.json на CVM.
- Пример вывода при использовании SAS3008:
В этом случае правильная команда — SAS3IRCU .
Обратите внимание на строку «led_address»: «sas3ircu:0,1:0» :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Пример вывода при использовании SAS3400/3800 (или новее):
В этом случае использование SAS3IRCU было бы опрометчиво. Вместо этого используйте команду storcli . Информацию о StorCLI см. в статье KB-10951 .
Обратите внимание на строку «led_address»: «storcli:0» .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Определите проблемные диски
- Проверьте веб-консоль Prism на наличие неисправного диска. В представлении «Диаграмма» отсутствующий диск отображается красным или серым цветом.
- Проверьте веб-консоль Prism на наличие предупреждений о дисках или используйте следующую команду, чтобы проверить диски, генерирующие сообщения об ошибках.
nutanix@cvm$ ncli alert ls - Проверьте, нет ли на каких-либо узлах смонтированных дисков. Два выхода должны совпадать численно.
- Проверьте диски, смонтированные на CVM (контроллерной виртуальной машине).
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Проверьте физические диски в CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Убедитесь, что все диски находятся в состоянии «Онлайн» и обозначены как «Обычный» .
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Проверьте диски, смонтированные на CVM (контроллерной виртуальной машине).
- Проверьте ожидаемое количество дисков в кластере.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lВыходные данные приведенной выше команды должны быть суммой выходных данных шагов 1c.i и 1c.ii.
Бывают случаи, когда число может быть выше или ниже ожидаемого. Итак, это важный показатель, который можно сравнить с дисками, перечисленными в шаге 1b.
- Найдите лишние или недостающие диски.
nutanix@cvm$ ncli disk ls - Убедитесь, что все диски указаны как смонтированные rw (чтение-запись), а не ro (только чтение).
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Выявление проблем с узлами дисков
- Идентификатор потерянного диска
Это идентификатор диска, который системы больше не используют, но не был удален должным образом. Симптомы включают появление дополнительного идентификатора диска, указанного в выводе ncli disk ls .
Чтобы исправить потерянный идентификатор диска:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueУбедитесь, что вы проверили серийный номер диска и что устройство отсутствует в системе. Кроме того, убедитесь, что все диски заполняются с помощью lsscsi , mount , df -h и подсчитываются диски для полного заполнения.
- Неисправный диск и/или отсутствующий диск
Проверьте, виден ли диск контроллеру, поскольку это устройство, на шине которого находится диск. Можно использовать следующие команды:
- lspci — отображает устройства PCI, видимые CVM.
- Устройство NVME — контроллер энергонезависимой памяти: твердотельный накопитель Intel Corporation PCIe Data Center (версия 01).
- Контроллер SAS3008 — контроллер SCSI с последовательным подключением: LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (версия 02) — LSI.
- Контроллер SAS2308 (Dell) — контроллер SCSI с последовательным подключением: LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (версия 05).
- MegaRaid LSI 3108 (Dell) — контроллер шины RAID: LSI Logic/Symbios Logic MegaRAID SAS-3 3108 [Invader] (ред. 02).
- LSI SAS3108 (UCS) — контроллер SCSI с последовательным подключением: LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (версия 02).
- lsiutil — отображает вид карт HBA (адаптера главной шины) для портов и указывает, находятся ли порты в состоянии UP. Если порт не работает, либо устройство не ответило, либо порт или соединение с устройством плохие. Скорее всего проблема в устройстве (диске).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi — список обнаруженных устройств шины SCSI, включая любые жесткие диски или твердотельные накопители (кроме NVME, который не проходит через контроллер SATA).
- sas3ircu — сообщает положение слота и состояние диска. Это полезно при отсутствии дисков или проверке того, что диски находятся в правильном слоте. (НЕ запускайте следующую команду на оборудовании Lenovo HX, так как это может привести к зависанию и перезагрузке HBA)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli — сообщает об ошибках диска, аналогично lsiutil. Также сообщает положение слота и состояние диска.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Проверьте dmesg CVM на наличие сообщений LSI mpt3sas. Обычно мы должны видеть одну запись для каждого физического слота. ( В приведенном ниже примере показано, что адрес SAS «0x5000c5007286a3f5» неоднократно проверяется из-за неисправного/неисправного диска. Обратите внимание, что другие адреса обнаруживаются один раз, а подозреваемый опрашивается повторно. )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl — если Hades укажет, что диск проверяется smartctl 3 раза в час, он автоматически выходит из строя.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- См. KB-8094 для устранения неполадок с помощью smartctl .
- Проверьте наличие автономных дисков с помощью проверки NCC disk_online_check .
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Дополнительную информацию по устранению неполадок с автономными дисками см. в статье KB 1536 .
- Убедитесь, что диски видны с помощью утилиты LSI Config. Это может быть полезно для исключения потенциальных проблем driver или конфигурацией CVM/гипервизора, которые могут помешать вам обнаружить определенные диски. Утилита LSI Config Utility предоставляет вам интерфейс непосредственно к прошивке HBA, не полагаясь на программную операционную систему. Его можно использовать для выполнения многих задач, которые вы можете делать с помощью «lsiutil»: (а) проверить, обнаружен ли диск в определенном слоте, (б) проверить скорость соединения с диском, (в) активировать светодиодный маяк на конкретном диске. На платформах G6 и G7 меню конфигурации LSI отключено по умолчанию, поэтому вам необходимо включить его в BIOS , прежде чем вы сможете его использовать. На платформах G8 необходимо просматривать подключенные диски непосредственно через меню BIOS .
- G8: просмотр подключенных дисков напрямую через BIOS
- Войдите в меню BIOS , нажав клавишу DEL на заставке «Nutanix» во время загрузки узла.
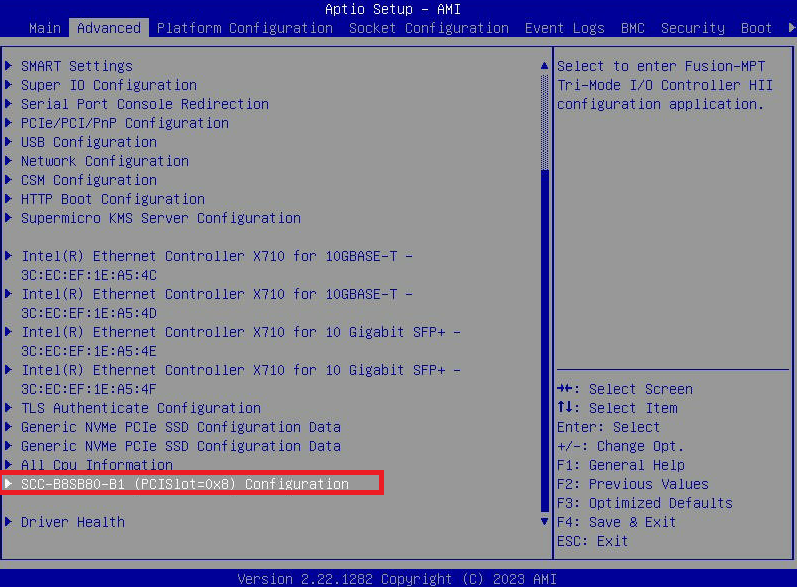
- Перейдите на вкладку « Дополнительно » и выберите « Конфигурация SCC-B8SB80-B1 (PCISlot=0x8) ». Так называется опция меню на 3060-G8. На других моделях он может называться немного иначе.
- G8: просмотр подключенных дисков напрямую через BIOS
- lspci — отображает устройства PCI, видимые CVM.
- Идентификатор потерянного диска
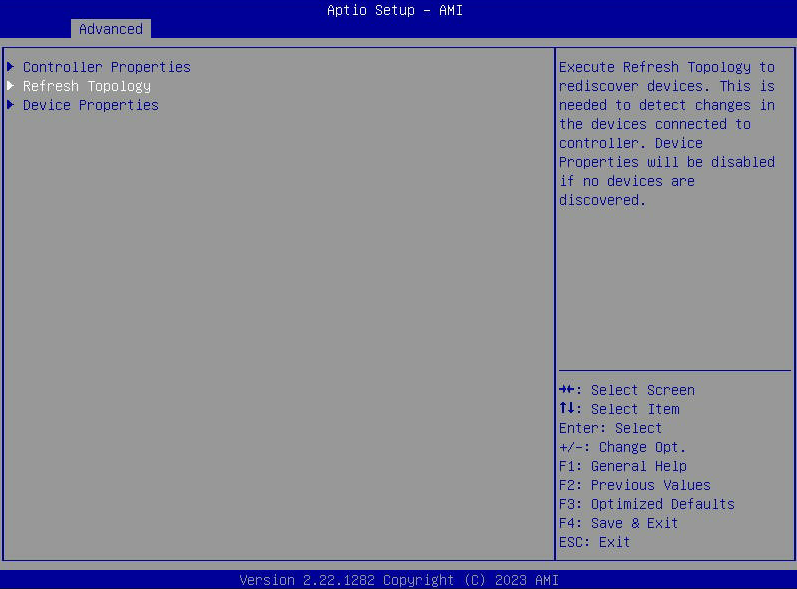
- Если опция «Свойства устройства» неактивна, выберите «Обновить топологию».
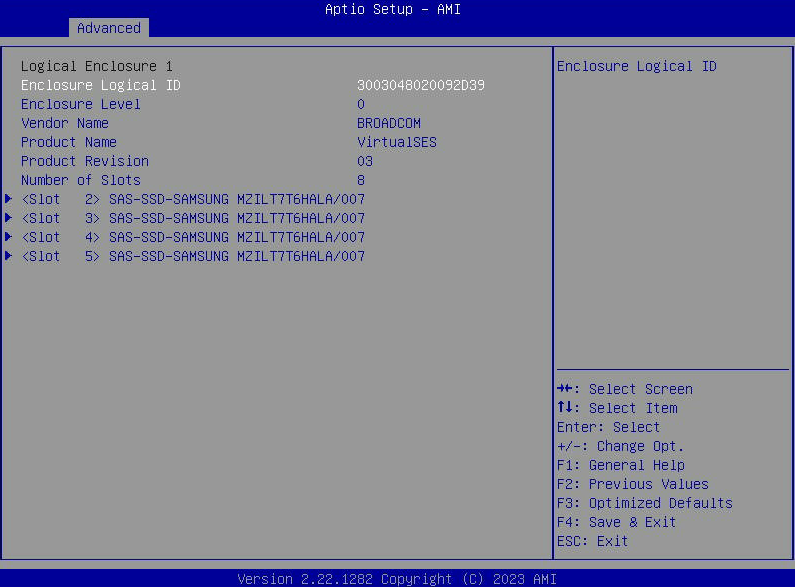
- Выберите «Свойства диска», чтобы просмотреть список дисков SATA, видимых хосту.
- G6 и G7: Как включить и получить доступ к OPROM LSI HBA
- Войдите в меню BIOS , нажав клавишу DEL на заставке «Nutanix» во время загрузки узла.
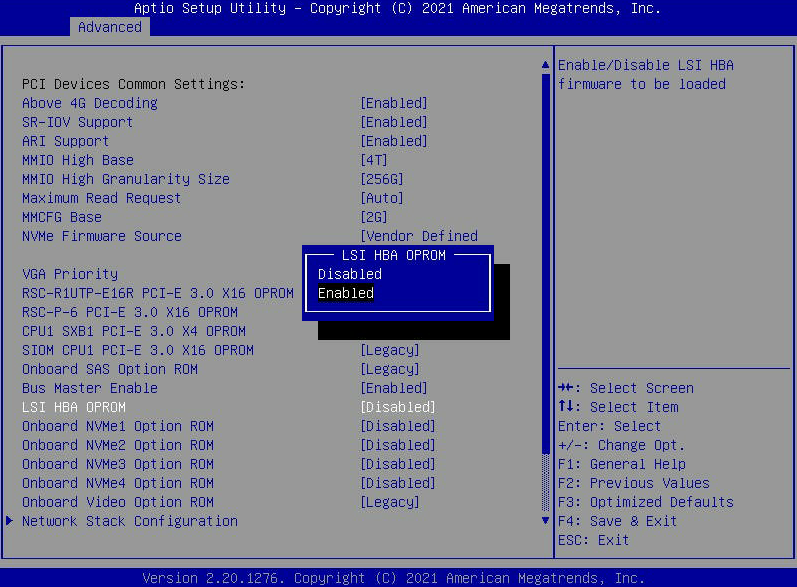
- Перейдите на вкладку «Дополнительно» и найдите «LSI HBA OPROM». Установите для этого параметра значение «Включено». Затем нажмите «F4», чтобы «Сохранить и выйти» из меню BIOS . Это приведет к перезагрузке узла.
- Примечание. После получения необходимой информации обязательно вернитесь в BIOS и ОТКЛЮЧИТЕ OPROM. Вы также можете нажать F3, чтобы загрузить оптимизированные настройки по умолчанию, что вернет BIOS к исходным заводским настройкам, при которых OPROM отключен.
- При следующей загрузке найдите экран под названием «Avago Technologies MPT SAS3 BIOS » и нажмите CRTL+C, чтобы войти в «Утилиту настройки SAS».
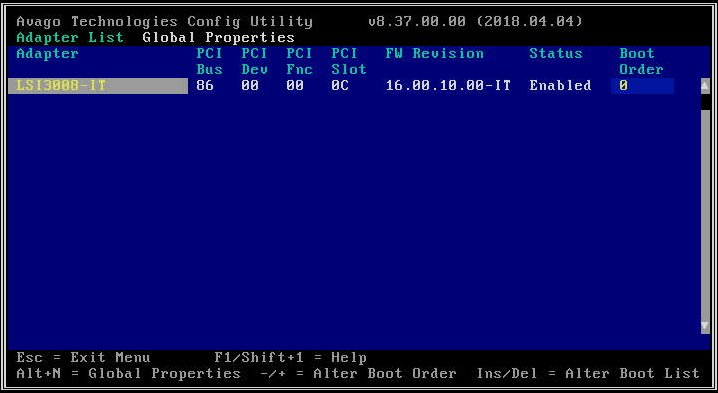
- Зайдя в утилиту настройки, выберите интересующую вас карту HBA. Многоузловые модели (2U4N, 2U2N) будут иметь максимум одну карту HBA, а одноузловые платформы (2U1N) могут иметь до трех. В системах с несколькими HBA каждый HBA будет обслуживать различное подмножество дисков на каждом узле.
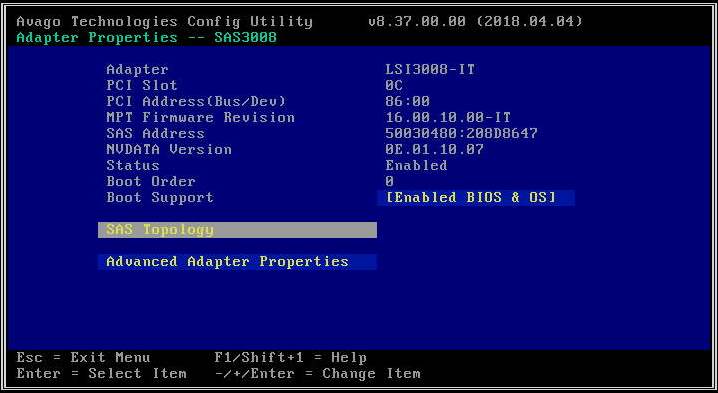
- На следующем экране выберите «Топология SAS», а затем «Устройства прямого подключения», чтобы просмотреть информацию о дисках, связанных с этим HBA.
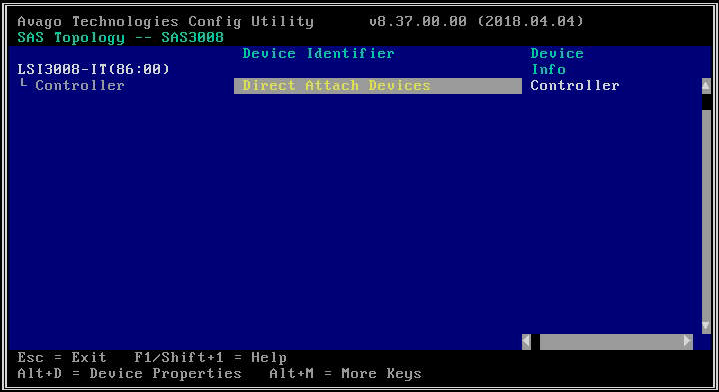
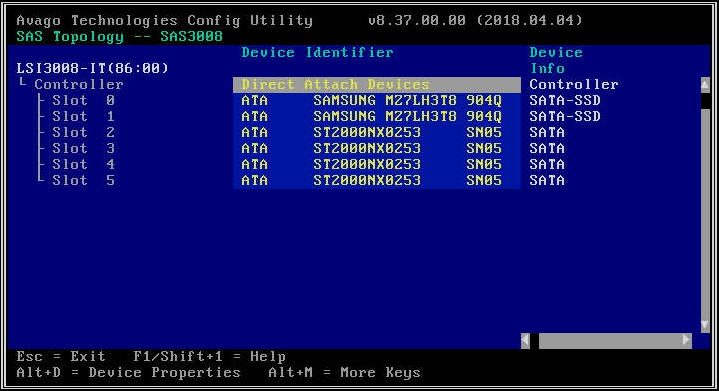
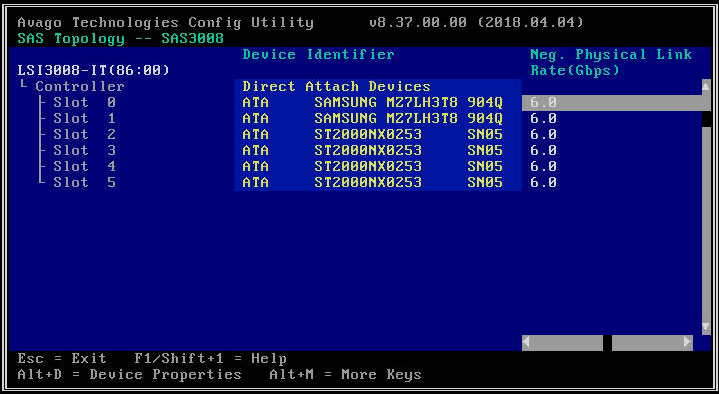
- Если выбранный вами адаптер HBA вообще не обнаруживает никаких дисков, он сообщит «Нет устройств для отображения».
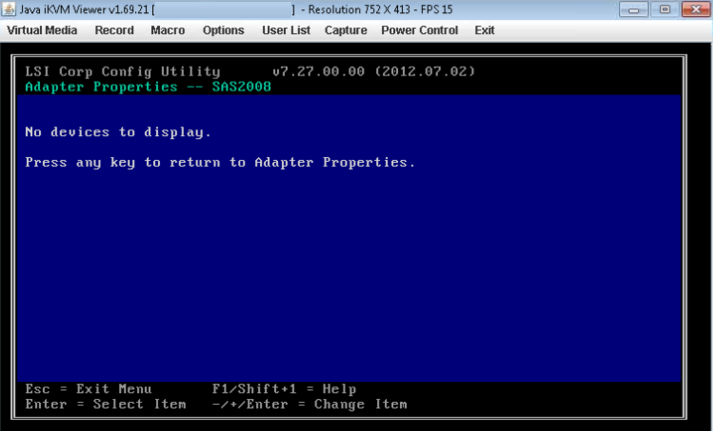
- Может быть случай, когда диск НЕ работает в lsiutil , обычно после замены или обновления дисков. Когда все вышеперечисленные проверки проведены, а диск по-прежнему не виден, сравните старый и новый диск «дисковый лоток или лоток». Убедитесь, что тип тот же. Могут быть случаи, когда отправляется диск неправильного типа, и он неправильно вставляется в отсек для диска, поэтому не обнаруживается контроллером.

- Определите тип узла или проблемный узел.
Запустите ncli host ls и найдите соответствующий идентификатор узла. Местоположение конкретного слота узла, серийный номер узла и тип узла — это важная информация, которую необходимо документировать в случае повторяющихся проблем. Это также помогает отслеживать проблемы с HBA, расположением и типами узлов. - Определите возникновение неисправности.
- Проверьте журнал Звездных врат. В журнале stargate.INFO за соответствующий период указывается, обнаружил ли Stargate проблему с диском и отправил ее в диспетчер дисков (Hades) для проверки, или были ли другие ошибки при доступе к диску. Используйте идентификационный номер диска и серийный номер для поиска в журнале Stargate на соответствующем узле, в котором находится диск.
- Журнал Hades содержит информацию об видимых дисках и их состоянии. Он также проверяет, какой диск является метаданными или диском куратора, и выбирает один, если он еще не существовал в системе или был удален/исчез из системы. Проверьте журнал Hades.
- Проверьте df -h в /home/nutanix/data/logs/sysstats/df.INFO , чтобы узнать, когда диск в последний раз был смонтирован.
- Проверьте /home/nutanix/data/logs/sysstats/iostat.INFO , чтобы узнать, когда устройство было замечено в последний раз.
- Проверьте /home/log/messages на наличие ошибок на устройстве, в частности, используя имя устройства, например, sda или sdc.
- Проверьте dmesg на наличие ошибок на контроллере или устройстве. Запустить dmesg | less для текущих сообщений в кольце или посмотрите записанный вывод dmesg в /var/log .
- Определите причину сбоя диска.
- Проверьте, когда CVM в последний раз запускался, если последние данные об использовании диска были недоступны. Опять же, обратитесь к журналам Звездных врат и Аида.
- Проверьте журнал Звездных врат во время сбоя диска. Stargate отправляет диск в Hades, чтобы проверить, не отвечает ли он в течение заданного времени, и устанавливает тайм-аут работы с этим диском. Различные ошибки и версии представляют это по-разному, поэтому всегда ищите по идентификатору диска и серийному номеру диска.
- Проверьте количество сбоев диска.
Если диск в этом слоте вышел из строя более одного раза и диск был заменен, это будет указывать на потенциальную проблему с шасси в этот момент. - Проверьте, показывает ли lsiutil ошибки.
Если lsiutil показывает ошибки равномерно в нескольких слотах, это может указывать на неисправность контроллера. - Проверьте известные проблемы с микропрограммой диска на наличие ошибок диска.
- Если это G8, версия MCU 1.1A или выше, а также были обновлены объединительные платы:
См. этот документ: NX-G8: CPLD объединительной платы Nutanix, CPLD материнской платы и руководство по обновлению встроенного ПО Multinode EC . - Если это G8, проверьте, что микропрограмма контроллера LSI имеет версию 25.00.00 или выше:
Существуют исправления, связанные со стабильностью SSD при использовании обрезки, которые исправляют экземпляр, который приводит к появлению ошибок PHY на дисках и нестабильности. С точки зрения устранения неполадок также важно использовать прошивку версии 25.00.00 или выше.
Примечание. Идентификатор события: 191 , G-Sense_Error_Rate в выводе « smartctl » для жестких дисков Seagate можно безопасно игнорировать, если не происходит снижения производительности. Значение G-Sense_Error_Rate указывает только на адаптацию жесткого диска к обнаружению ударов или вибрации. Seagate рекомендует не доверять этим значениям, поскольку этот счетчик динамически изменяет пороговое значение во время выполнения.
Статьи по теме
- Оригинальная статья на портале Nutanix: Nutanix KB Статья: 1113
- Целевая страница Nutanix
