HDD、SSD 和 HBA 故障排除
HDD、SSD 和 HBA 故障排除
HDD、SSD 和 HBA 故障排除
描述
当驱动器出现可恢复错误、警告或完全故障时,Stargate 服务会将磁盘标记为脱机。如果检测到磁盘在一小时内脱机 3 次,则会自动将其从集群中移除,并生成警报( KB-4158或KB-6287 )。
如果 Prism 中生成警报,则必须更换磁盘。无需执行故障排除步骤。
注意:如果在 AWS 上的 Nutanix 集群中遇到故障磁盘,一旦确认磁盘发生故障,将继续谴责相应节点。谴责受影响的节点将用相同类型的新裸机实例替换它。
解决方案
一旦更换磁盘,就应该执行 NCC 健康检查以确保最佳集群健康。
但是,如果一开始没有生成警报或者需要进一步分析,则可以使用以下步骤进一步排除故障。
开始故障排除之前,请验证 HBA 控制器的类型。
警告:
对 LSI 3408 或更高版本的 HBA 使用 SAS3IRCU 命令可能会导致 NMI 事件,从而导致存储不可用。
使用以下命令之前,请确认 HBA 控制器。
要确定使用了哪种类型的 HBA,请查找位于CVM上的 /etc/nutanix/hardware_config.json 中的控制器名称。
- SAS3008使用时的输出示例:
在这种情况下,命令SAS3IRCU是正确的命令。
请注意“led_address”:“sas3ircu:0,1:0”行:
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - 使用 SAS3400/3800(或更新版本)时的输出示例:
在这种情况下,使用 SAS3IRCU 是不明智的。请改用storcli命令。有关 StorCLI 的信息,请参阅KB-10951 。
注意“led_address”:“storcli:0”行。
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
识别有问题的磁盘
- 检查 Prism Web 控制台中是否存在故障磁盘。在图表视图中,您可以看到红色或灰色表示丢失的磁盘。
- 检查 Prism Web 控制台中的磁盘警报,或使用以下命令检查生成故障消息的磁盘。
nutanix@cvm$ ncli alert ls - 检查是否有任何节点缺少已安装的磁盘。两个输出应在数字上匹配。
- 检查安装在 CVM(控制器 VM)上的磁盘。
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - 检查 CVM 中的物理磁盘。
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - 检查磁盘的状态是否全部为Online且指示为Normal 。
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- 检查安装在 CVM(控制器 VM)上的磁盘。
- 验证集群中预期的磁盘数量。
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -l上述命令的输出应该是步骤 1c.i 和 1c.ii 的输出之和。
在某些情况下,该数字可能高于或低于预期。因此,这是一个重要的指标,可以与步骤 1b 中列出的磁盘进行比较。
- 查找多余的或丢失的磁盘。
nutanix@cvm$ ncli disk ls - 检查所有磁盘是否已安装为 rw(读写)而不是 ro(只读)。
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
确定磁盘节点的问题
- 孤立磁盘 ID
这是系统不再使用但未正确删除的磁盘 ID。症状包括在ncli disk ls的输出中看到一个额外的磁盘 ID。
要修复孤立磁盘 ID,请执行以下操作:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=true确保验证磁盘序列号,并且该设备不在系统中。此外,确保使用lsscsi 、 mount 、 df -h填充所有磁盘,并计算磁盘数量以达到满盘填充。
- 磁盘故障和/或磁盘丢失
检查磁盘是否对控制器可见,因为它是磁盘驻留在其总线上的设备。可以使用以下命令:
- lspci - 显示 CVM 看到的 PCI 设备。
- NVME 设备 - 非易失性内存控制器: Intel公司 PCIe 数据中心 SSD(rev 01)。
- SAS3008 控制器 - 串行连接 SCSI 控制器:LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3(rev 02) - LSI。
- SAS2308 控制器(戴尔) - 串行连接 SCSI 控制器:LSI Logic / Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2(rev 05)。
- MegaRaid LSI 3108(戴尔) - RAID 总线控制器:LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader](rev 02)。
- LSI SAS3108 (UCS) - 串行连接 SCSI 控制器:LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3(rev 02)。
- lsiutil - 显示端口的 HBA(主机总线适配器)卡视图以及端口是否处于 UP 状态。如果端口未启动,则设备没有响应,或者端口或与设备的连接不良。最可能的问题出在设备(磁盘)上。
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi - 列出看到的 SCSI 总线设备,包括任何 HDD 或 SSD(NVME 除外,它不通过 SATA 控制器)。
- sas3ircu - 报告插槽位置和磁盘状态。它对于丢失磁盘或验证磁盘是否位于正确的插槽中很有用。(请勿在Lenovo HX 硬件上运行以下命令,因为它可能会导致 HBA 锁定和重置)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli - 报告与 lsiutil 类似的驱动器错误。还报告插槽位置和磁盘状态。
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - 检查 CVM 的dmesg中是否有 LSI mpt3sas 消息。我们通常应该看到每个物理插槽都有一个条目。(以下示例显示由于磁盘损坏/故障,SAS 地址“0x5000c5007286a3f5”被反复检查。请注意其他地址是如何被检测到一次的,并且可疑地址正在被反复轮询。 )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl - 如果 Hades 指示某个磁盘在一小时内被 smartctl 检查了 3 次,则该磁盘自动失败。
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- 有关使用smartctl进行故障排除的信息,请参阅KB-8094 。
- 使用 NCC check disk_online_check检查脱机磁盘。
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- 有关离线磁盘的进一步故障排除,请参阅KB 1536 。
- 确认是否从 LSI 配置实用程序中看到磁盘。这对于排除可能阻止您检测某些驱动器的潜在driver或 CVM/虚拟机管理程序配置问题很有用。LSI 配置实用程序为您提供直接与 HBA 固件的接口,而无需依赖软件操作系统。它可用于执行许多使用“lsiutil”可以执行的相同操作:(a) 检查是否在特定插槽中检测到磁盘,(b) 检查磁盘链接速度,(c) 激活特定驱动器上的 LED 信标。在 G6 和 G7 平台上,LSI 配置菜单默认处于禁用状态,因此您必须在BIOS中启用它才能使用它。在 G8 平台上,您必须直接通过BIOS菜单查看连接的驱动器。
- G8:直接通过BIOS查看连接的驱动器
- 在节点启动时,在“Nutanix”启动画面上按 DEL 键进入BIOS菜单。
- 转到“高级”选项卡并选择“ SCC-B8SB80-B1 (PCISlot=0x8) 配置”。这是 3060-G8 上的菜单选项名称。在其他型号上,它的名称可能略有不同。
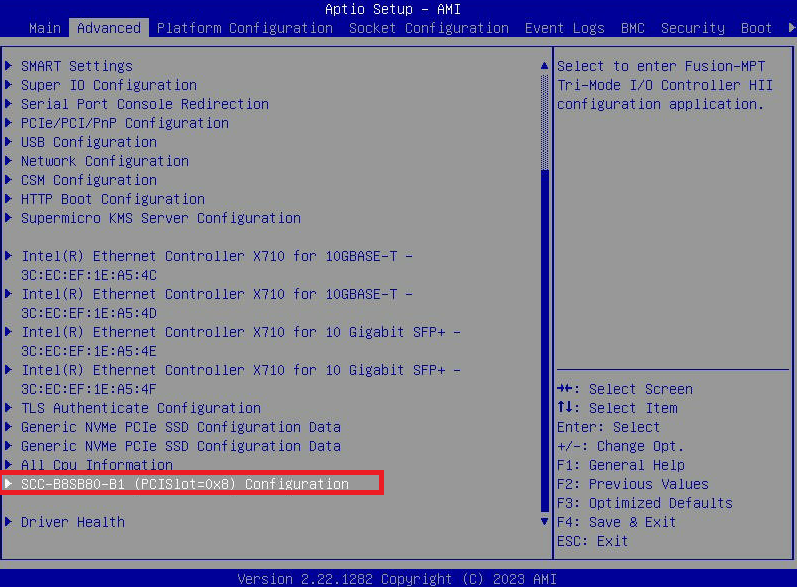
- G8:直接通过BIOS查看连接的驱动器
- lspci - 显示 CVM 看到的 PCI 设备。
- 孤立磁盘 ID
- 如果“设备属性”选项显示为灰色,请选择“刷新拓扑”。
- 选择“驱动器属性”来查看主机可见的 SATA 驱动器列表。
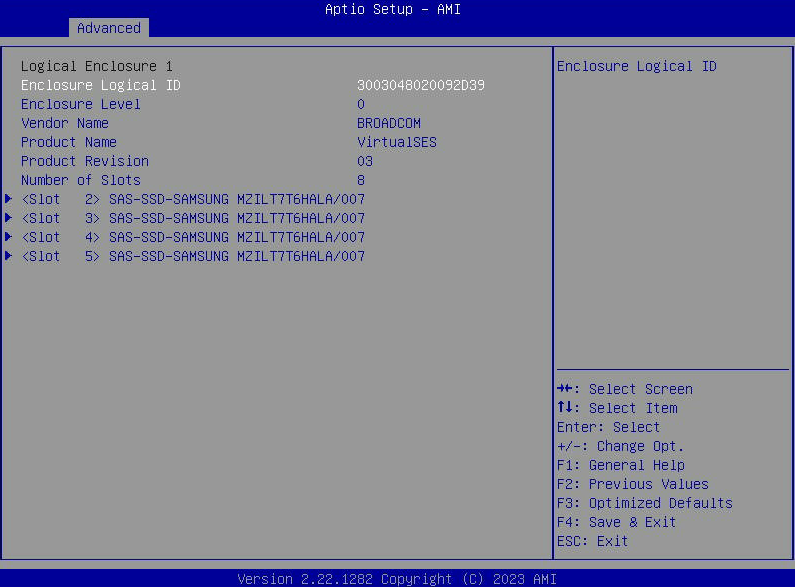
- G6 和 G7:如何启用和访问 LSI HBA OPROM
- 在节点启动时,在“Nutanix”启动画面上按 DEL 键进入BIOS菜单。
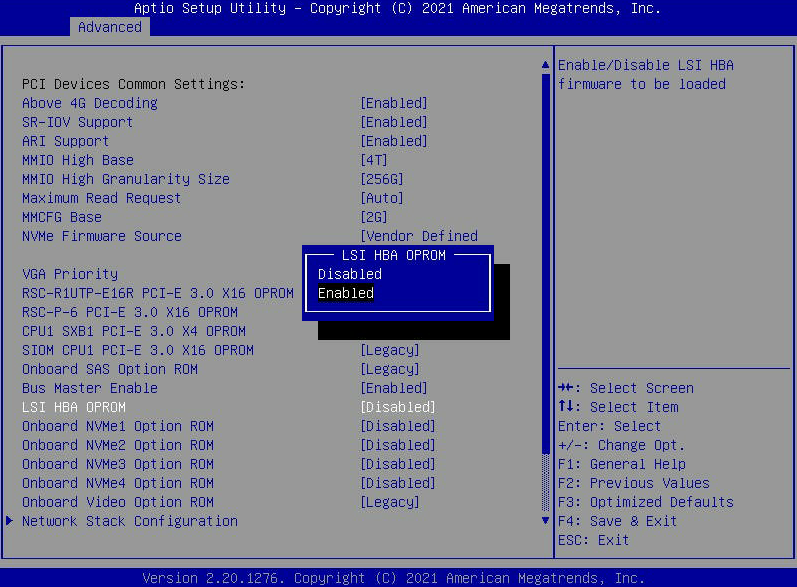
- 转到“高级”选项卡并找到“LSI HBA OPROM”。将其设置为“已启用”。然后按“F4”键“保存并退出” BIOS菜单。这将导致节点重新启动。
- 注意:获得所需信息后,请务必返回BIOS并禁用 OPROM。您也可以按 F3 加载优化默认值,这将使BIOS恢复到其原始出厂设置,即禁用 OPROM。
- 在下次启动时,查找标题为“Avago Technologies MPT SAS3 BIOS ”的屏幕,然后按 CRTL+C 进入“SAS 配置实用程序”。
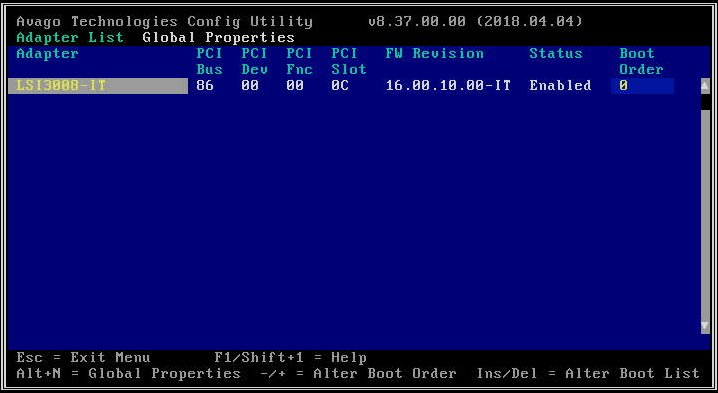
- 进入配置实用程序后,选择您感兴趣的 HBA 卡。多节点型号(2U4N、2U2N)最多只有一个 HBA 卡,而单节点平台(2U1N)可能有多达三个。在多 HBA 系统中,每个 HBA 将为每个节点上的不同驱动器子集提供服务。
- 在下一个屏幕上,选择“SAS 拓扑”,然后选择“直接连接设备”以查看与该 HBA 关联的驱动器的信息。
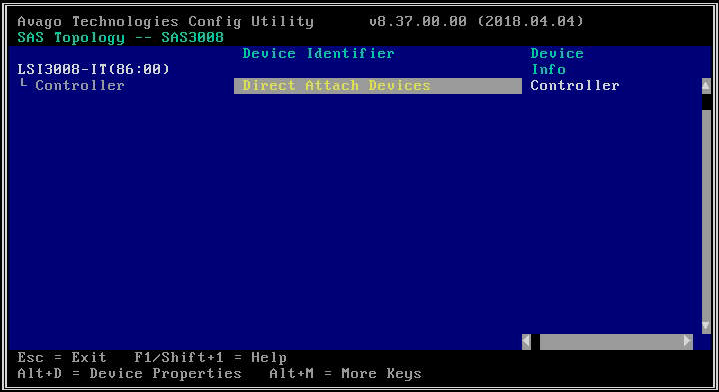
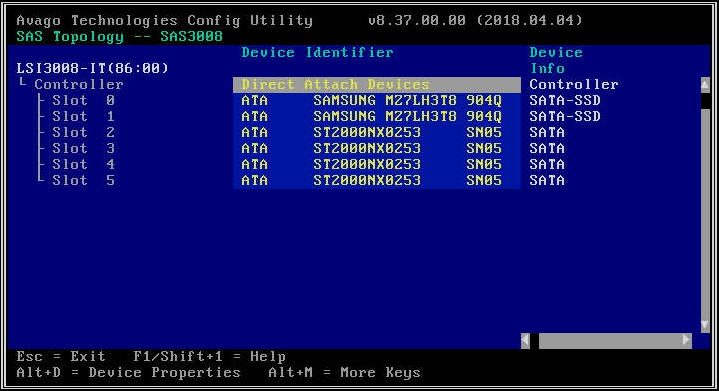
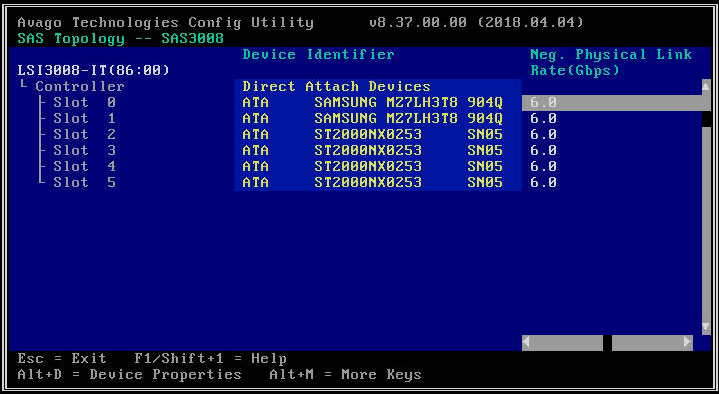
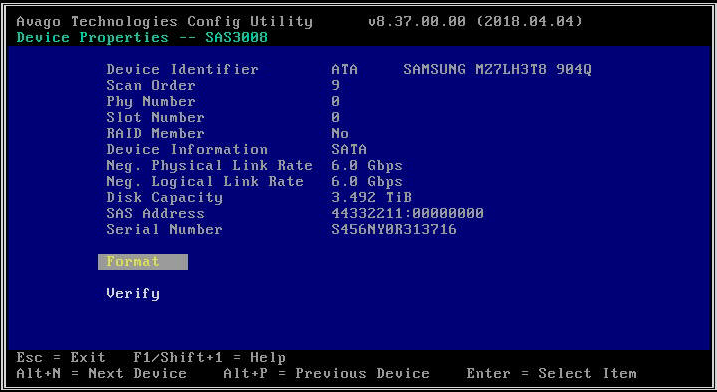
- 如果您选择的 HBA 根本没有检测到任何驱动器,它将报告“没有可显示的设备”。
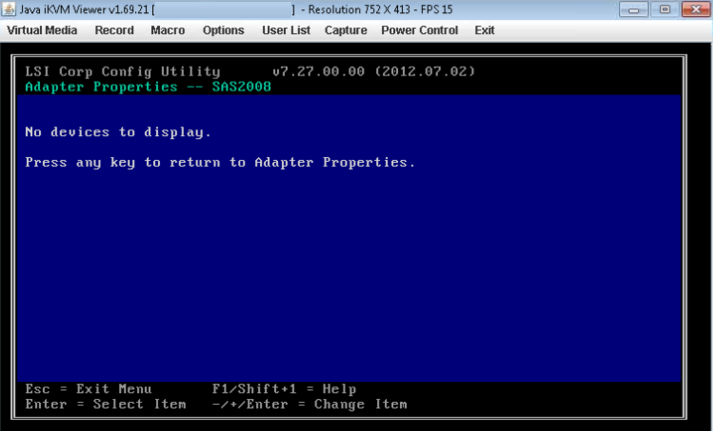
- 可能会出现磁盘在lsiutil中处于关闭状态的情况,通常是在更换或升级磁盘后。执行完上述所有检查后,如果仍然看不到磁盘,请比较新旧磁盘“磁盘盒或托盘”。确保类型相同。可能会出现发送的磁盘类型不正确,无法正确安装在磁盘托架中,因此控制器无法检测到的情况。

- 识别节点类型或有问题的节点。
运行ncli host ls并查找匹配的节点 ID。特定节点槽位置、节点序列和节点类型是记录重复出现的问题的重要信息。它还有助于跟踪 HBA、节点位置和节点类型的现场问题。 - 识别故障发生的情况。
- 检查 Stargate 日志。相应时间段的stargate.INFO日志表明 Stargate 是否发现磁盘存在问题并将其发送到磁盘管理器 (Hades) 进行检查,或者在访问磁盘时出现其他错误。使用磁盘 ID 号和序列号在磁盘所在相应节点的 Stargate 日志中进行 grep。
- Hades 日志包含有关其看到的磁盘及其运行状况的信息。它还会检查哪个磁盘是元数据磁盘或 Curator 磁盘,如果系统中不存在磁盘或磁盘已从系统中删除/消失,则会选择一个磁盘。检查 Hades 日志。
- 检查/home/nutanix/data/logs/sysstats/df.INFO中的df -h以查看磁盘最后一次被挂载的时间。
- 检查/home/nutanix/data/logs/sysstats/iostat.INFO以查看设备最后一次出现的时间。
- 检查/home/log/messages中是否存在设备错误,具体使用设备名称,例如 sda 或 sdc。
- 检查dmesg以查找控制器或设备上的错误。运行dmesg | less以查看环中的当前消息,或查看/var/log中记录的 dmesg 输出。
- 确定磁盘故障的原因。
- 如果磁盘的最后使用数据不可用,请检查 CVM 上次启动的时间。再次参考 Stargate 和 Hades 日志。
- 检查磁盘故障前后的 Stargate 日志。Stargate 向 Hades 发送磁盘,以检查它是否在给定时间内没有响应,以及该磁盘的操作是否超时。不同的错误和版本对此有不同的表示,因此请始终按磁盘 ID 和磁盘序列进行搜索。
- 检查磁盘故障的数量。
如果此插槽中的驱动器发生故障超过一次,并且磁盘被更换,则表明此时可能存在底盘问题。 - 检查 lsiutil 是否显示错误。
如果lsiutil在多个插槽上均匀显示错误,则可能表示控制器有故障。 - 检查驱动器 FW 中是否存在已知的磁盘错误。
- 如果这是 G8,则 MCU 版本为 1.1A 或更高版本,并且背板也已升级:
参考本文档: NX-G8:Nutanix 背板 CPLD、主板 CPLD 和多节点 EC 固件手动升级指南。 - 如果这是 G8,请检查 LSI 控制器 FW 是否为 25.00.00 或更高版本:
在使用 trim 时,存在与 SSD 稳定性相关的修复,可纠正导致驱动器上出现 PHY 错误和不稳定的实例。从故障排除的角度来看,使用 FW 25.00.00 或更高版本也很重要。
注意:事件 ID:191 ,除非性能下降,否则可以安全地忽略 Seagate HDD 的“ smartctl ”输出中的G-Sense_Error_Rate。G -Sense_Error_Rate 值仅表示 HDD 适应冲击或振动检测。Seagate 建议不要信任这些值,因为此计数器在运行时会动态更改阈值。
相关文章
- Nutanix 门户中的原始文章: Nutanix KB 文章:1113
- Nutanix 登陆页面
