Risoluzione dei problemi di HDD, SSD e HBA
Risoluzione dei problemi di HDD, SSD e HBA
Risoluzione dei problemi di HDD, SSD e HBA
Descrizione
Quando un'unità presenta errori reversibili, avvisi o un guasto completo, il servizio Stargate contrassegna il disco come offline. Se il disco viene rilevato offline 3 volte nell'arco di un'ora, viene rimosso automaticamente dal cluster e viene generato un avviso ( KB-4158 o KB-6287 ).
Se viene generato un avviso in Prism, il disco deve essere sostituito. Non è necessario eseguire passaggi per la risoluzione dei problemi.
NOTA: se viene rilevato un disco guasto in un Nutanix Clusters su AWS, una volta confermato che il disco è guasto, procedere a condannare il rispettivo nodo. Condannare il nodo interessato lo sostituirà con una nuova istanza bare metal dello stesso tipo.
Soluzione
Una volta sostituito il disco, è necessario eseguire un controllo dello stato NCC per garantire l'integrità ottimale del cluster.
Tuttavia, se non è stato generato un avviso in primo luogo o è necessaria un'ulteriore analisi, è possibile utilizzare i passaggi seguenti per risolvere ulteriormente il problema.
Prima di iniziare la risoluzione dei problemi, verificare il tipo di controller HBA.
Attenzione:
L'utilizzo del comando SAS3IRCU su un HBA LSI 3408 o superiore può causare eventi NMI che potrebbero portare all'indisponibilità della memoria.
Confermare il controller HBA prima di utilizzare i seguenti comandi.
Per determinare quale tipo di HBA viene utilizzato, cercare il nome del controller situato in /etc/nutanix/hardware_config.json sul CVM.
- Esempio dell'output quando viene utilizzato SAS3008:
In questo caso, il comando SAS3IRCU è il comando corretto da utilizzare.
Nota la riga "led_address": "sas3ircu:0,1:0" :
"node": { "storage_controllers": [ { "subsystem": "15d9:0808", "name": "LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3", "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": null, "location": { "access_plane": 1, "cell_x": 6, "width": 6, "cell_y": 2, "height": 1 }, "led_address": "sas3ircu:0,1:0" }, - Esempio dell'output quando viene utilizzato SAS3400/3800 (o versione successiva):
In questo caso l'utilizzo di SAS3IRCU sarebbe sconsiderato. Utilizzare invece il comando storcli . Per informazioni su StorCLI fare riferimento a KB-10951 .
Nota la riga "led_address": "storcli:0" .
"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },"storage_controllers_v2": [ { "subsystem": "15d9:1b64", "name": "Broadcom / LSI Fusion-MPT 12GSAS/PCIe Secure SAS38xx", "hba_hints": { "sas_address": "0x50030480208d9939" }, "mapping": [ { "slot_designation": "1", "hba_address": "0", "slot_id": 1, "location": { "access_plane": 1, "height": 3, "width": 4, "cell_y": 0, "cell_x": 78 }, "led_address": "storcli:0" },
Identificare i dischi problematici
- Controllare la console Web Prism per il disco guasto. Nella vista Diagramma, puoi vedere il rosso o il grigio per il disco mancante.
- Controlla la console Web Prism per gli avvisi del disco o utilizza il comando seguente per verificare la presenza di dischi che generano messaggi di errore.
nutanix@cvm$ ncli alert ls - Controlla se in qualche nodo mancano i dischi montati. I due output dovrebbero corrispondere numericamente.
- Controllare i dischi montati sul CVM (Controller VM).
nutanix@cvm$ allssh "df -h | grep -i stargate-storage | wc -l" - Controllare i dischi fisici nel CVM.
nutanix@cvm$ allssh "lsscsi | grep -v DVD-ROM | wc -l" - Controlla se lo stato dei dischi è tutto Online e indicato come Normale .
nutanix@cvm$ ncli disk ls | egrep -i -E 'Online|Status'
- Controllare i dischi montati sul CVM (Controller VM).
- Convalidare il numero previsto di dischi nel cluster.
nutanix@cvm$ ncli disk ls | grep -i 'Status' | wc -lL'output del comando precedente dovrebbe essere la somma degli output dei passaggi 1c.i e 1c.ii.
Ci sono casi in cui il numero può essere superiore o inferiore al previsto. Si tratta quindi di un parametro importante che può essere paragonato ai dischi elencati nel passaggio 1b.
- Cerca dischi extra o mancanti.
nutanix@cvm$ ncli disk ls - Controlla che tutti i dischi siano indicati come montati rw (lettura-scrittura) e non ro (sola lettura).
nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*rw' nutanix@cvm$ sudo mount | grep -E 'stargate-storage.*ro'
Identificare i problemi con i nodi dei dischi
- ID del disco orfano
Si tratta di un ID disco che i sistemi non utilizzano più ma che non è stato rimosso correttamente. I sintomi includono la visualizzazione di un ID disco aggiuntivo elencato nell'output di ncli disk ls .
Per correggere l'ID del disco orfano:
nutanix@cvm$ ncli disk rm-start id= force=truenutanix@cvm$ ncli disk rm-start id= force=trueAssicurati di convalidare il numero di serie del disco e che il dispositivo non sia nel sistema. Inoltre, assicurati che tutti i dischi vengano popolati utilizzando lsscsi , mount , df -h e contando i dischi per il popolamento dell'intero disco.
- Disco guasto e/o disco mancante
Controlla se il disco è visibile al controller poiché è il dispositivo sul cui bus risiede il disco. È possibile utilizzare i seguenti comandi:
- lspci : visualizza i dispositivi PCI visti da CVM.
- Dispositivo NVME - Controller di memoria non volatile: Intel Corporation PCIe Data Center SSD (rev 01).
- Controller SAS3008 - Controller SCSI collegato in serie: LSI Logic / Symbios Logic SAS3008 PCI-Express Fusion-MPT SAS-3 (rev 02) - LSI.
- Controller SAS2308 (Dell) - Controller SCSI collegato in serie: LSI Logic/Symbios Logic SAS2308 PCI-Express Fusion-MPT SAS-2 (rev 05).
- MegaRaid LSI 3108 (Dell) - Controller bus RAID: LSI Logic / Symbios Logic MegaRAID SAS-3 3108 [Invader] (rev 02).
- LSI SAS3108 (UCS) - Controller SCSI collegato in serie: LSI Logic / Symbios Logic SAS3108 PCI-Express Fusion-MPT SAS-3 (rev 02).
- lsiutil : visualizza la prospettiva delle schede HBA (Host Bus Adapter) delle porte e se le porte sono in stato UP. Se una porta non è attiva, il dispositivo non ha risposto oppure la porta o la connessione al dispositivo sono difettose. Il problema più probabile è il dispositivo (disco).
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/lsiutil -a 12,0,0 20 - lsscsi : elenca i dispositivi bus SCSI visti che includono qualsiasi HDD o SSD (eccetto NVME, che non passa attraverso il controller SATA).
- sas3ircu - riporta la posizione dello slot e lo stato del disco. È utile per i dischi mancanti o per verificare che i dischi siano nello slot corretto. (NON eseguire il seguente comando sull'hardware Lenovo HX poiché potrebbe causare blocchi e ripristini dell'HBA)
nutanix@cvm$ sudo /home/nutanix/cluster/lib/lsi-sas/sas3ircu 0 display - storcli : segnala errori di unità simili a lsiutil. Segnala anche la posizione dello slot e lo stato del disco.
sudo ~/cluster/lib/storcli/storcli64 /call/pall show phyerrorcounters|tail -n+6 - Show phy error counts in concise output sudo ~/cluster/lib/storcli/storcli64 /call/pall show |tail -n+6 - Show detected speeds and interfaces sudo ~/cluster/lib/storcli/storcli64 /call show all - Show everything - Controllare il dmesg del CVM per i messaggi LSI mpt3sas. In genere dovremmo vedere una voce per ogni slot fisico. ( L'esempio seguente mostra che l'indirizzo SAS "0x5000c5007286a3f5" viene controllato ripetutamente a causa di un disco danneggiato/guasto. Notare come gli altri indirizzi vengono rilevati una volta e il sospetto viene ripetutamente interrogato. )
nutanix@cvm$ sudo dmesg | grep "detecting\: handle" [ 3.693032] mpt3sas_cm0: detecting: handle(0x0009), sas_address(0x5000c40074c6d56d), phy(0) [ 3.702423] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 3.941624] mpt3sas_cm0: detecting: handle(0x000b), sas_address(0x4431221106000000), phy(6) [ 4.191170] mpt3sas_cm0: detecting: handle(0x000c), sas_address(0x5000c500856f9e51), phy(1) [ 4.211879] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5006286a3f5), phy(2) [ 4.213080] mpt3sas_cm0: detecting: handle(0x000e), sas_address(0x5000c500856fa075), phy(3) [ 4.231194] mpt3sas_cm0: detecting: handle(0x000f), sas_address(0x5000c500856f9735), phy(4) [ 4.245974] mpt3sas_cm0: detecting: handle(0x0010), sas_address(0x5000c50084e02b31), phy(5) [ 4.942347] mpt3sas_cm0: detecting: handle(0x000a), sas_address(0x4431221107000000), phy(7) [ 5.214032] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) [ 6.215092] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) . . [ 12.233236] mpt3sas_cm0: detecting: handle(0x000d), sas_address(0x5000c5007286a3f5), phy(2) - smartctl - se Hades indica che un disco viene controllato da smartctl 3 volte in un'ora, viene automaticamente fallito.
nutanix@cvm$ sudo smartctl -x /dev/sdX -T permissive- Vedi KB-8094 per la risoluzione dei problemi con smartctl .
- Verifica la presenza di dischi offline utilizzando NCC check disk_online_check .
nutanix@cvm$ ncc health_checks hardware_checks disk_checks disk_online_check- Consulta l'articolo KB 1536 per ulteriori informazioni sulla risoluzione dei problemi relativi ai dischi offline.
- Confermare se i dischi vengono visualizzati da LSI Config Utility. Ciò può essere utile per escludere potenziali problemi di configurazione di driver o CVM/Hypervisor che potrebbero impedire il rilevamento di determinate unità. L'utilità di configurazione LSI fornisce un'interfaccia direttamente al firmware HBA senza fare affidamento su un sistema operativo software. Può essere usato per fare molte delle cose che puoi fare con "lsiutil": (a) Controllare se un disco viene rilevato in un particolare slot, (b) Controllare la velocità di collegamento del disco, (c) Attivare un segnalatore LED su un disco particolare. Sulle piattaforme G6 e G7, il menu LSI Config è disabilitato per impostazione predefinita, quindi è necessario abilitarlo nel BIOS prima di poterlo utilizzare. Sulle piattaforme G8 è necessario visualizzare le unità collegate direttamente tramite il menu BIOS .
- G8: visualizza le unità collegate direttamente tramite il BIOS
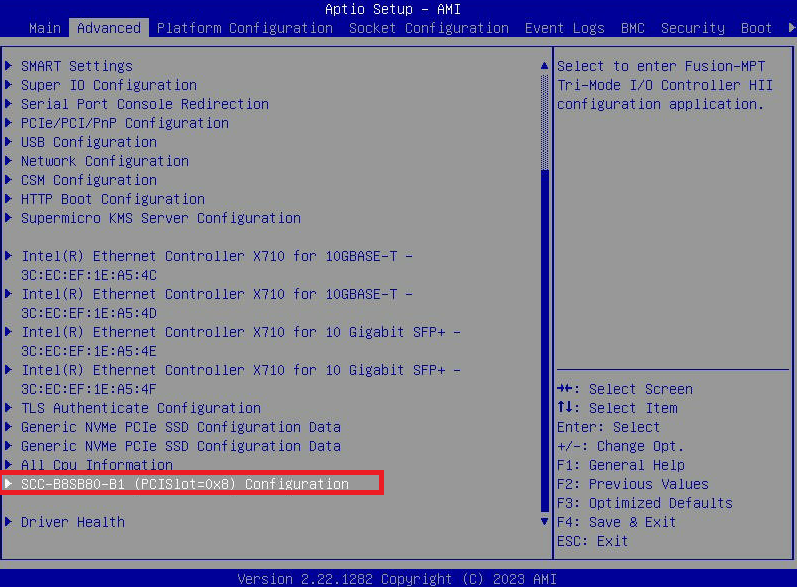
- Accedi al menu BIOS premendo il tasto CANC nella schermata iniziale "Nutanix" durante l'avvio del nodo.
- Andare alla scheda " Avanzate " e selezionare " Configurazione SCC-B8SB80-B1 (PCISlot=0x8) ". Questo è il nome dell'opzione di menu sul 3060-G8. Potrebbe avere un nome leggermente diverso su altri modelli.
- G8: visualizza le unità collegate direttamente tramite il BIOS
- lspci : visualizza i dispositivi PCI visti da CVM.
- ID del disco orfano
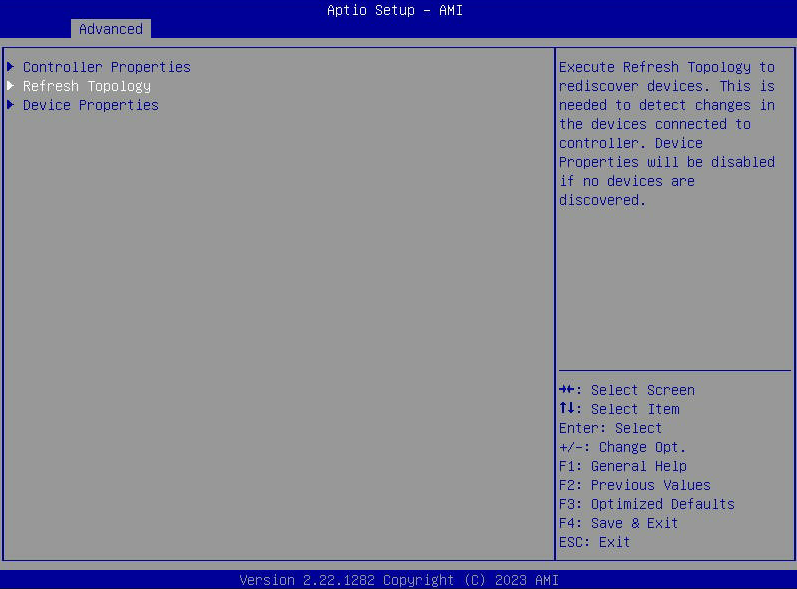
- Se l'opzione "Proprietà dispositivo" è disattivata, seleziona "Aggiorna topologia".
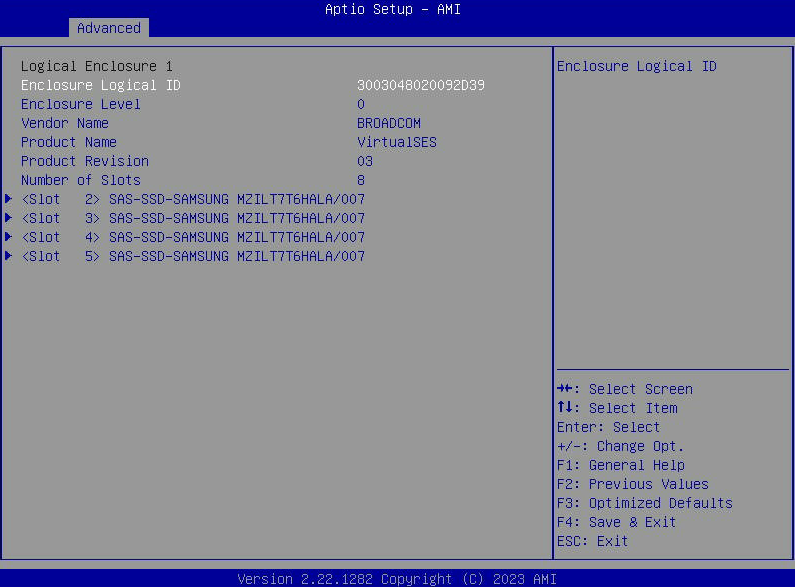
- Seleziona "Proprietà unità" per visualizzare un elenco delle unità SATA visibili all'host.
- G6 e G7: come abilitare e accedere alla OPROM HBA LSI
- Accedi al menu BIOS premendo il tasto CANC nella schermata iniziale "Nutanix" durante l'avvio del nodo.
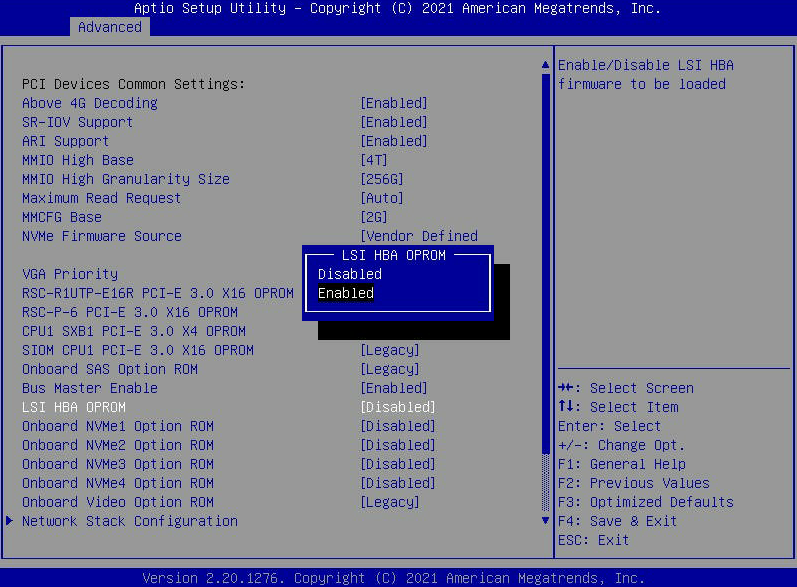
- Vai alla scheda "Avanzate" e trova "LSI HBA OPROM". Impostalo su "Abilitato". Quindi premi "F4" per "Salva ed esci" nel menu BIOS . Ciò causerà il riavvio del nodo.
- Nota: dopo aver ottenuto le informazioni necessarie, assicurati di tornare nel BIOS e DISABILITARE l'OPROM. Puoi anche premere F3 per caricare le impostazioni predefinite ottimizzate, che riporteranno il BIOS alle impostazioni di fabbrica originali in cui l'OPROM è disabilitata.
- Al successivo avvio, cercare la schermata intitolata "Avago Technologies MPT SAS3 BIOS " e premere CRTL+C per accedere all'"Utilità di configurazione SAS".
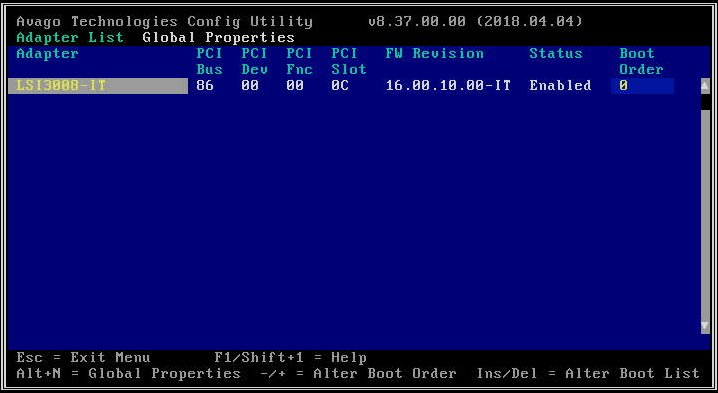
- Una volta all'interno dell'utilità di configurazione, seleziona la scheda HBA che ti interessa. I modelli multinodo (2U4N, 2U2N) avranno solo un massimo di una scheda HBA, mentre le piattaforme a nodo singolo (2U1N) possono averne fino a tre. Nei sistemi multi-HBA, ciascun HBA servirà un diverso sottoinsieme di unità su ciascun nodo.
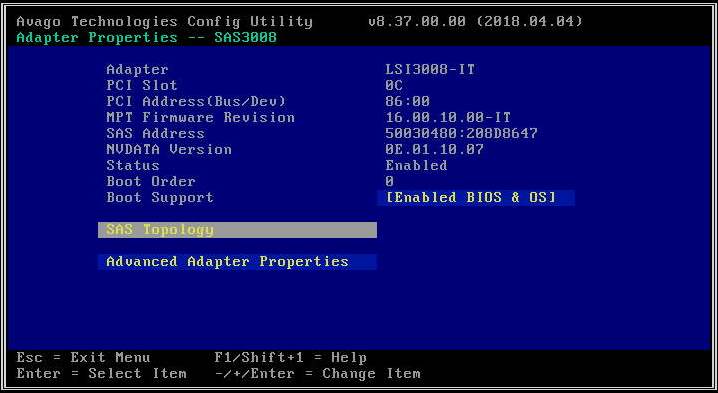
- Nella schermata successiva, seleziona "Topologia SAS" e quindi "Dispositivi a collegamento diretto" per visualizzare le informazioni sulle unità associate a tale HBA.
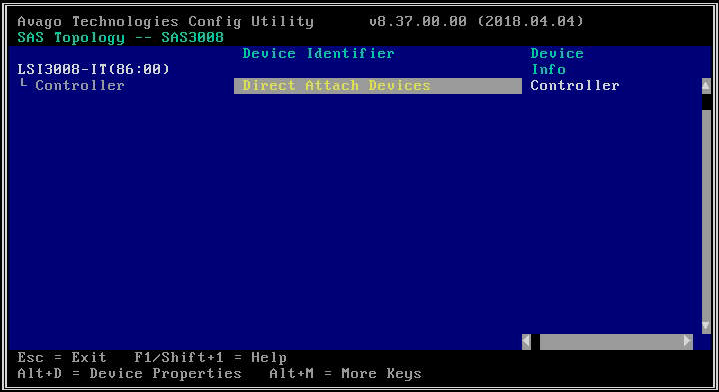
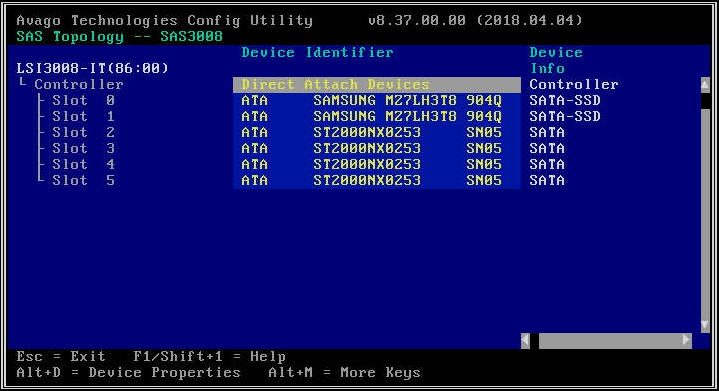
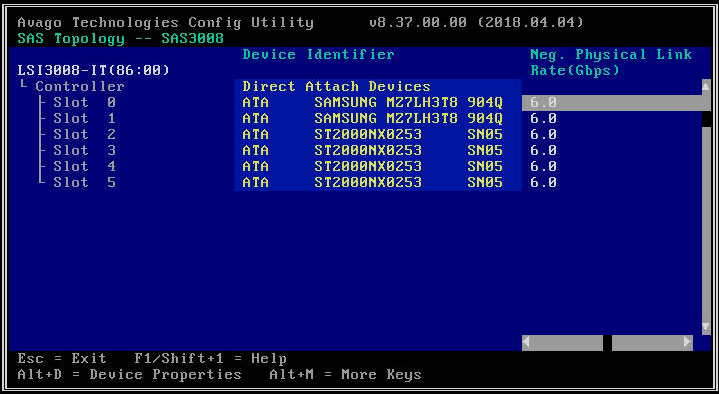
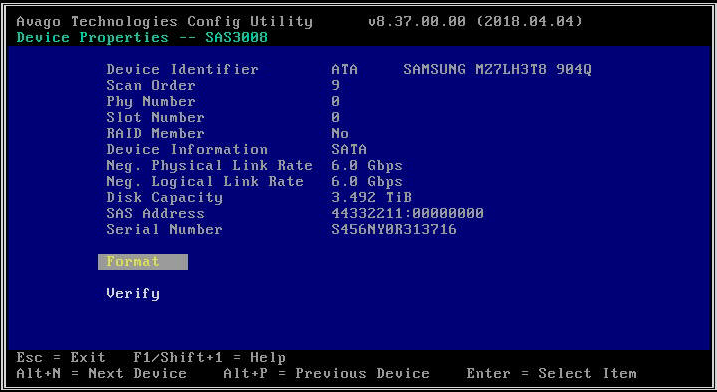
- Se l'HBA selezionato non rileva alcuna unità, riporterà "Nessun dispositivo da visualizzare".
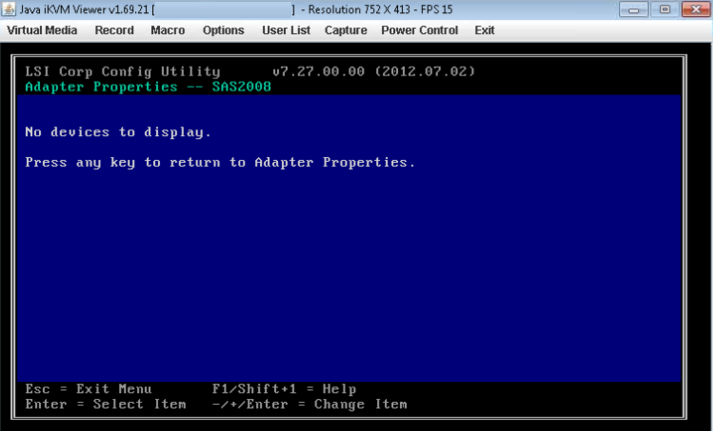
- Potrebbe verificarsi un caso in cui il disco è DOWN in lsiutil , solitamente dopo una sostituzione o un aggiornamento dei dischi. Una volta eseguiti tutti i controlli di cui sopra e il disco non è ancora visibile, confrontare il vecchio e il nuovo disco "disk caddy or vassoio". Assicurati che il tipo sia lo stesso. Possono verificarsi casi in cui viene inviato un tipo di disco errato che non viene inserito correttamente nell'alloggiamento del disco e quindi non viene rilevato dal controller.

- Identificare il tipo di nodo o il nodo problematico.
Esegui ncli host ls e trova l'ID del nodo corrispondente. La posizione specifica dello slot del nodo, il numero di serie del nodo e il tipo di nodo sono informazioni importanti da documentare in caso di problemi ricorrenti. Aiuta anche a tenere traccia dei problemi sul campo relativi agli HBA, alle posizioni dei nodi e ai tipi di nodi. - Identificare il verificarsi dell'errore.
- Controlla il registro dello Stargate. Il registro stargate.INFO per il periodo corrispondente indica se Stargate ha riscontrato un problema con un disco e lo ha inviato a Gestione disco (Hades) per il controllo o ha riscontrato altri errori durante l'accesso al disco. Utilizzare il numero ID del disco e il numero di serie da ricercare nel registro Stargate sul nodo corrispondente in cui si trova il disco.
- Il registro Hades contiene informazioni sui dischi rilevati e sullo stato dei dischi. Controlla inoltre quale disco è metadati o disco Curatore e ne seleziona uno se non esiste già nel sistema o è stato rimosso/scomparso dal sistema. Controlla il registro dell'Ade.
- Controlla df -h in /home/nutanix/data/logs/sysstats/df.INFO per vedere quando il disco è stato visto l'ultima volta come montato.
- Controlla /home/nutanix/data/logs/sysstats/iostat.INFO per vedere quando è stato visto l'ultima volta il dispositivo.
- Controllare /home/log/messages per eventuali errori sul dispositivo, in particolare utilizzando il nome del dispositivo, ad esempio sda o sdc.
- Controlla dmesg per eventuali errori sul controller o sul dispositivo. Esegui dmesg | less per i messaggi correnti nel ring, oppure guarda l'output registrato di dmesg in /var/log .
- Identificare la causa del guasto del disco.
- Controllare quando è stato avviato l'ultimo CVM se gli ultimi dati sull'utilizzo del disco non erano disponibili. Ancora una volta, fai riferimento ai registri di Stargate e Hades.
- Controlla il registro Stargate nel momento in cui si verifica il guasto del disco. Stargate invia un disco ad Hades per verificare se non risponde in un dato tempo e attiva il timeout su quel disco. Diversi errori e versioni lo rappresentano in modo diverso, quindi cerca sempre per ID disco e seriale del disco.
- Controlla il conteggio degli errori del disco.
Se un'unità si guasta più di una volta in questo slot e il disco viene sostituito, a quel punto indicherebbe un potenziale problema allo chassis. - Controlla se lsiutil mostra errori.
Se lsiutil mostra errori in modo uniforme su più slot, può indicare un controller difettoso. - Verificare la presenza di problemi noti con il firmware dell'unità per gli errori del disco.
- Se si tratta di un G8 la cui versione MCU è 1.1A o successiva e anche i backplane sono stati aggiornati:
Fai riferimento a questo documento: NX-G8: Guida all'aggiornamento manuale del firmware Nutanix Backplane CPLD, Motherboard CPLD e Multinode EC . - Se si tratta di un G8, verificare che il firmware del controller LSI sia 25.00.00 o successivo:
Sono disponibili correzioni relative alla stabilità dell'SSD quando è in uso il trim che correggono un'istanza che causa la visualizzazione di errori PHY sulle unità e instabilità. È anche importante, dal punto di vista della risoluzione dei problemi, avere la versione FW 25.00.00 o successiva.
Nota: ID evento: 191 , G-Sense_Error_Rate nell'output " smartctl " per gli HDD Seagate può essere tranquillamente ignorato a meno che non si verifichi un degrado delle prestazioni. Il valore G-Sense_Error_Rate indica solo che l'HDD si sta adattando al rilevamento di urti o vibrazioni. Seagate consiglia di non fidarsi di questi valori poiché questo contatore modifica dinamicamente la soglia durante il runtime.
Articoli correlati
- Articolo originale nel portale Nutanix: Nutanix KB Article: 1113
- Pagina di destinazione Nutanix
